万字干货:IM 会话列表卡顿优化实践
本文干货充足,篇幅较长,建议收藏后阅读,避免迷路。
一、背景
作为一款 IM 软件,会话列表是用户首先接触到的界面,会话列表滑动是否流畅对用户的体验有着很大的影响。随着功能的不断增加,会话列表上要展示的信息也越来越多。我们发现打完 Call 返回到会话列表界面进行滑动,可能出现严重的卡顿。于是我们开始对会话列表卡顿情况进行详细的分析。
二、卡顿的原因
提到卡顿原因,我们都会说是因为在 16ms 内无法完成渲染导致的。那么为什么需要在 16ms 内完成呢?以及在 16ms 以内需要完成什么工作?
2.1 刷新率(RefreshRate)与帧率(FrameRate)
刷新率指的是屏幕每秒刷新的次数,是针对硬件而言的。目前大部分的手机刷新率都在 60Hz(屏幕每秒钟刷新 60 次),有部分高端机采用的 120Hz(比如 iPad Pro)。
帧率是每秒绘制的帧数,是针对软件而言的。通常只要帧率与刷新率保持一致,我们看到的画面就是流畅的。所以帧率在 60FPS 时我们就不会感觉到卡。
如果帧率为每秒钟 60 帧,而屏幕刷新率为 30Hz,那么就会出现屏幕上半部分还停留在上一帧的画面,屏幕的下半部分渲染出来的就是下一帧的画面 —— 这种情况被称为画面撕裂;相反,如果帧率为每秒钟 30 帧,屏幕刷新率为 60Hz,那么就会出现相连两帧显示的是同一画面,这就出现了卡顿。
所以单方面的提升帧率或者刷新率是没有意义的,需要两者同时进行提升。
由于目前大部分 Android 机屏幕都采用的 60Hz 的刷新率,为了使帧率也能达到 60FPS,那么就要求在 16.67ms 内完成一帧的绘制(1000ms/60Frame = 16.666ms / Frame)。
2.2 VSYNC
由于显示器是从最上面一行像素开始,向下逐行刷新,所以从最顶端到最底部的刷新是有时间差的。
如果帧率(FPS)大于刷新率,那么就会出现前文提到的画面撕裂,如果帧率再大一点,那么下一帧的还没来得及显示,下下一帧的数据就覆盖上来了,中间这帧就被跳过了,这种情况被称为跳帧。
为了解决这种帧率大于刷新率的问题,引入了垂直同步的技术,简单来说就是显示器每隔 16ms 发送一个垂直同步信号(VSYNC),系统会等待垂直同步信号的到来,才进行一帧的渲染和缓冲区的更新,这样就把帧率与刷新率锁定。
2.3 系统是如何生成一帧的
在 Android4.0 以前,处理用户输入事件,绘制、栅格化都由 CPU 中应用主线程执行,很容易造成卡顿。主要原因在于主线程的任务太重,要处理很多事件,其次 CPU 中只有少量的 ALU 单元(算术逻辑单元),并不擅长做图形计算。
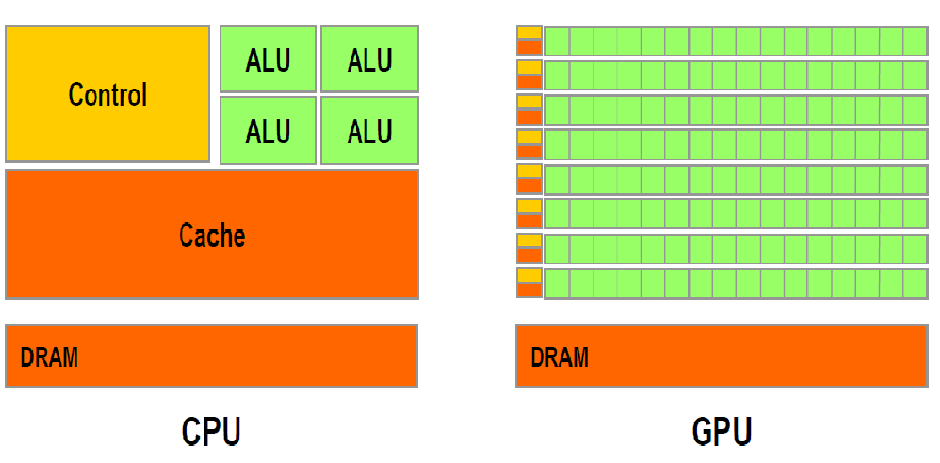
Android4.0 以后应用默认开启硬件加速。开启硬件加速以后,CPU 不擅长的图像运算就交给了 GPU 来完成,GPU 中包含了大量的 ALU 单元,就是为实现大量数学运算设计的(所以挖矿一般用 GPU)。硬件加速开启后还会将主线程中的渲染工作交给单独的渲染线程(RenderThread),这样当主线程将内容同步到 RenderThread 后,主线程就可以释放出来进行其他工作,渲染线程完成接下来的工作。
那么完整的一帧流程如下:
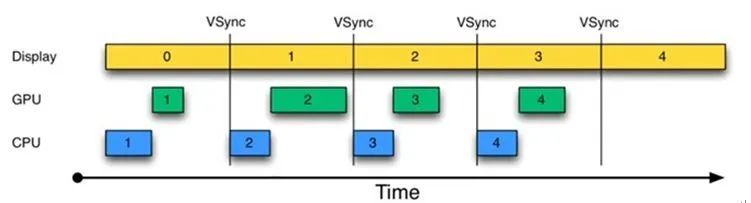
(1) 首先在第一个 16ms 内,显示器显示了第 0 帧的内容,CPU/GPU 处理完第一帧。
(2) 垂直同步信号到来后,CPU 马上进行第二帧的处理工作,处理完以后交给 GPU。显示器则将第一帧的图像显示出来。
整个流程看似没有什么问题,但是一旦出现帧率(FPS)小于刷新率的情况,画面就会出现卡顿。
图上的 A 和 B 分别代表两个缓冲区。因为 CPU/GPU处理时间超过了 16ms,导致在第二个 16ms 内,显示器本应该显示 B 缓冲区中的内容,现在却不得不重复显示 A 缓冲区中的内容,也就是掉帧了(卡顿)。
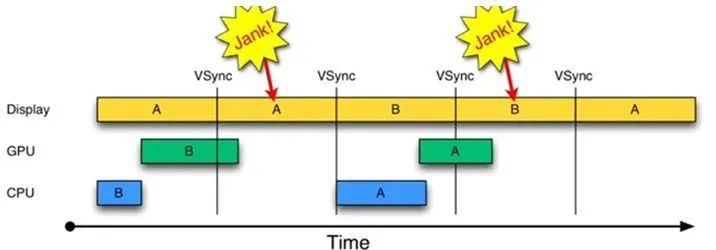
由于 A 缓冲区被显示器所占用,B 缓冲区被 GPU 所占用,导致在垂直同步信号 (VSync) 到来时 CPU 没办法开始处理下一帧的内容,所以在第二个 16ms内,CPU 并没有触发绘制工作。
2.4 三缓冲区(Triple Buffer)
为了解决帧率(FPS)小于屏幕刷新率导致的掉帧问题,Android4.1 引入了三级缓冲区。
在双缓冲区的时候,由于 Display 和 GPU 各占用了一个缓冲区,导致在垂直同步信号到来时 CPU 没有办法进行绘制。那么现在新增一个缓冲区,CPU 就能在垂直同步信号到来时进行绘制工作。
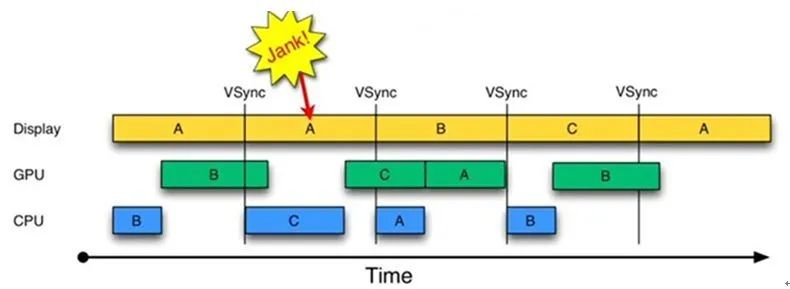
在第二个 16ms 内,虽然还是重复显示了一帧,但是在 Display 占用了 A 缓冲区,GPU 占用了 B 缓冲区的情况下,CPU 依然可以使用 C 缓冲区完成绘制工作,这样 CPU 也被充分地利用起来。后续的显示也比较顺畅,有效地避免了 Jank 进一步的加剧。
通过绘制的流程我们知道,出现卡顿是因为掉帧了,而掉帧的原因在于垂直同步信号到来时,还没有准备好数据用于显示。所以我们要处理卡顿,就要尽量缩短 CPU/GPU 绘制的时间,这样就能保证在 16ms 内完成一帧的渲染。
三、问题分析
有了以上的理论基础,我们开始分析会话列表卡顿的问题。由于 Boss 使用的 Pixel5 属于高端机,卡顿并不明显,我们特意从测试同学手中借来了一台中低端机。

先看一下优化之前的效果:
果然是很卡,看看手机刷新率是多少:

是 60Hz 没问题。
去高通网站上查询一下 SDM450 具体的架构:

可以看该手机的 CPU 是 8 核 A53 Processor。
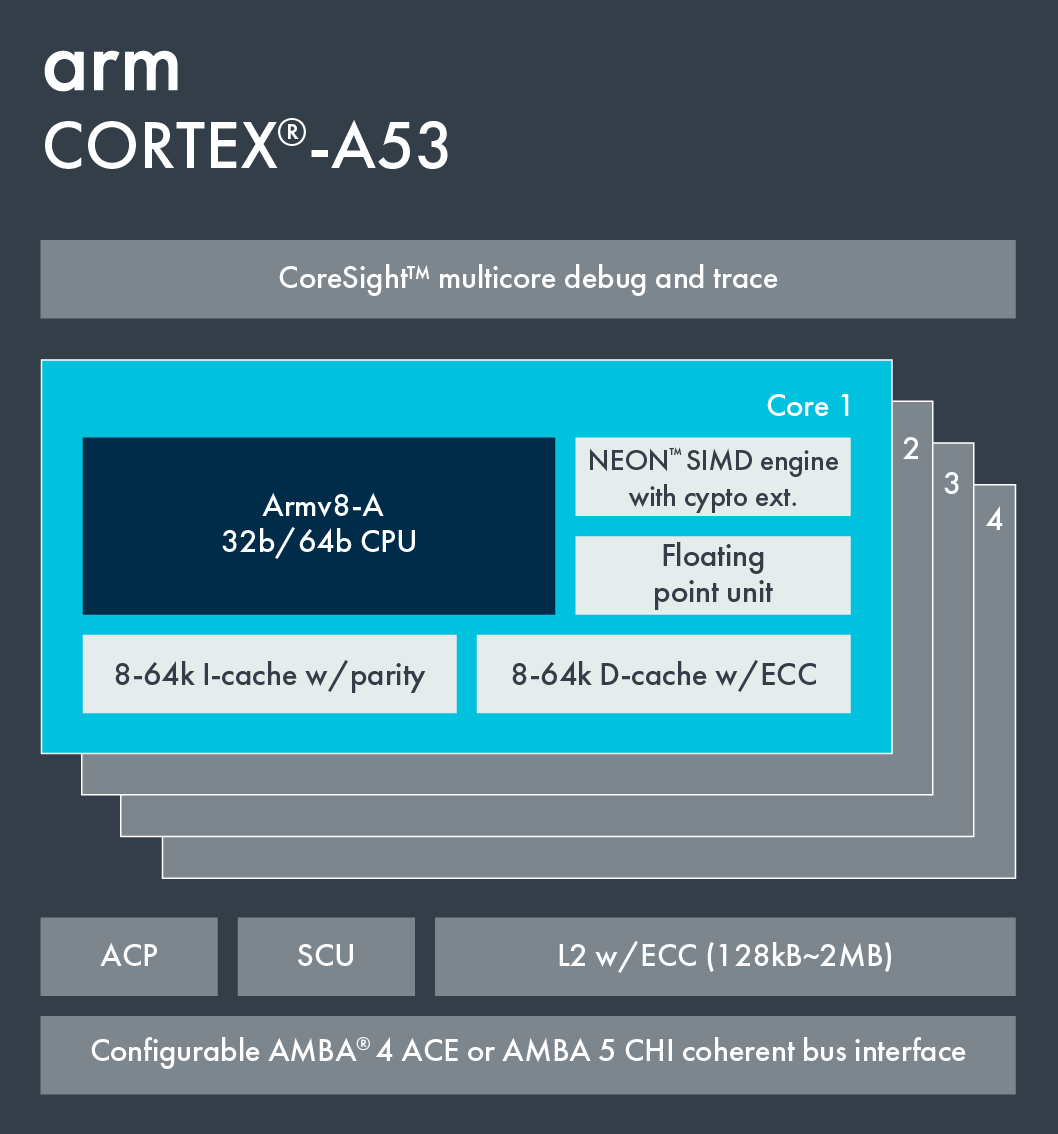
A53 Processor 一般在大小核架构中当作小核来使用,其主要作用是省电,那些性能要求很低的场景一般由它们负责,比如待机状态、后台执行等,而A53 也确实把功耗做到了极致。
在三星 Galaxy A20s 手机上,全都采用该 Processor,并且没有大核,那么处理速度自然不会很快,这也就要求我们的 APP 优化得更好才行。
在有了对手机大致的了解以后,我们使用工具来查看一下卡顿点。
首先打开系统自带的 GPU 呈现模式分析工具,对会话列表进行查看。
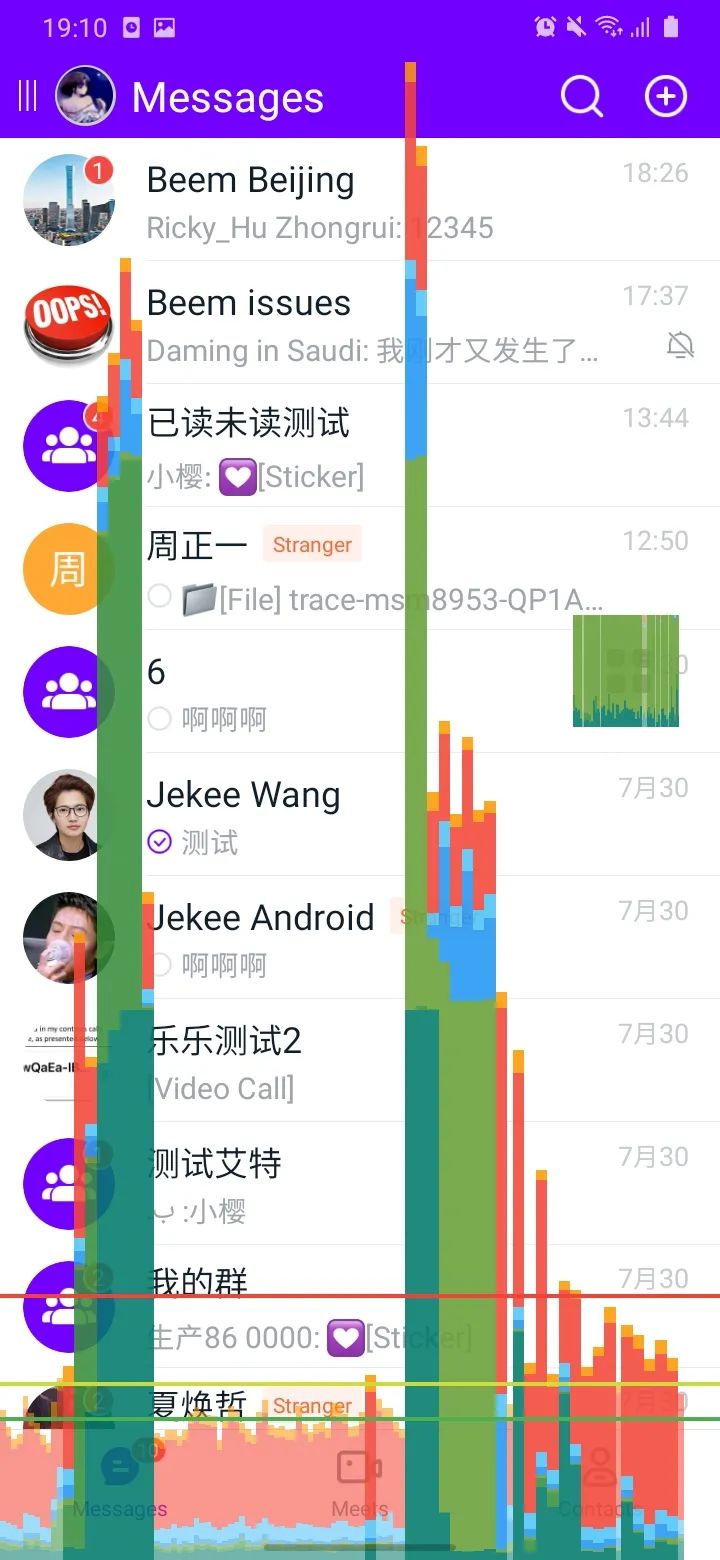
可以看见直方图已经高出了天际。在图中最下面有一条绿色的水平线(代表16ms),超过这条水平线就有可能出现掉帧。

根据 Google 给出的颜色对应表,我们来看看耗时的大概位置。首先我们要明确,虽然该工具叫 GPU 呈现模式分析工具,但是其中显示的大部分操作发生在 CPU 中。
其次根据颜色对照表大家可能也发现了,谷歌给出的颜色跟真机上的颜色对应不上。所以我们只能判断耗时的大概位置。
从我们的截图中可以看见,绿色部分占很大比例,其中一部分是 Vsync 延迟,另外一部分是输入处理+动画+测量/布局。
Vsync 延迟图标中给出的解释为两个连续帧之间的操作所花的时间。其实就是 SurfaceFlinger 在下一次分发 Vsync 的时候,会往 UI 线程的 MessageQueue 中插入一条 Vsync 到来的消息,而该消息并不会马上执行,而是等待前面的消息被执行完毕以后,才会被执行。所以 Vsync 延迟指的就是 Vsync 被放入 MessageQueue 到被执行之间的时间。这部分时间越长说明 UI 线程中进行的处理越多,需要将一些任务分流到其他线程中执行。
输入处理、动画、 测量/布局这部分都是垂直同步信号到达并开始执行 doFrame 方法时的回调。
void doFrame(long frameTimeNanos, int frame) {
//…省略无关代码
try {
Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Choreographer#doFrame");
AnimationUtils.lockAnimationClock(frameTimeNanos / TimeUtils.NANOS_PER_MS);
mFrameInfo.markInputHandlingStart();
//输入处理
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
mFrameInfo.markAnimationsStart();
//动画
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_INSETS_ANIMATION, frameTimeNanos);
mFrameInfo.markPerformTraversalsStart();
//测量/布局
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos);
} finally {
AnimationUtils.unlockAnimationClock();
Trace.traceEnd(Trace.TRACE_TAG_VIEW);
}这部分如果比较耗时,需要检查是否在输入事件回调中是否执行了耗时操作,或者是否有大量的自定义动画,又或者是否布局层次过深导致测量 View 和布局耗费太多的时间。
四、优化方案及实践
4.1 异步
有了大概的方向以后,我们开始对会话列表进行优化。
在问题分析中,我们发现 Vsync 延迟占比很大,所以我们首先想到的是将主线程中的耗时任务剥离出来,放到工作线程中执行。为了更快地定位主线程方法耗时,可以使用滴滴的 Dokit 或者腾讯的 Matrix 进行慢函数定位。
我们发现在会话列表的 ViewModel 中,使用了 LiveData 订阅了数据库中用户信息表的变更、群信息表的变更、群成员表的变更。只要这三张表有变化,都会重新遍历会话列表,进行数据更新,然后通知页面刷新。
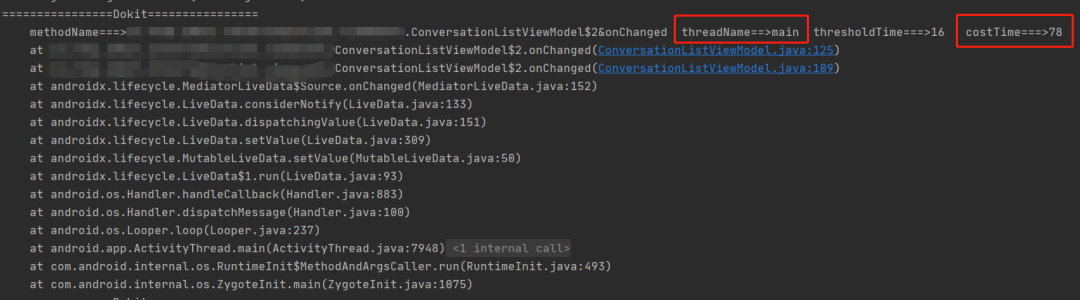
这部分逻辑在主线程中执行,耗时大概在 80ms 左右,如果会话列表多,数据库表数据变更大,这部分的耗时还会增加。
mConversationListLiveData.addSource(getAllUsers(), new Observer<List<User>>() {
@Override
public void onChanged(List<User> users) {
if (users != null && users.size() > 0) {
//遍历会话列表
Iterator<BaseUiConversation> iterable = mUiConversationList.iterator();
while (iterable.hasNext()) {
BaseUiConversation uiConversation = iterable.next();
//更新每个item上用户信息
uiConversation.onUserInfoUpdate(users);
}
mConversationListLiveData.postValue(mUiConversationList);
}
}
});既然这部分比较耗时,我们可以将遍历更新数据的操作放到子线程中执行,执行完毕以后再调用 postValue 方法通知页面进行刷新。
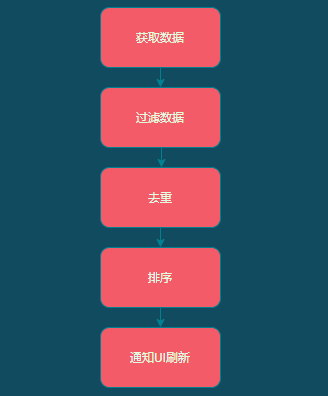

我们还发现每次进入会话列表时都需要从数据库中获取会话列表数据,加载更多时也会从数据库中读取会话数据。读取到会话数据以后,我们会对获取到的会话进行过滤操作,比如不是同一个组织下的会话则应该过滤掉。过滤完成以后会进行去重,如果该会话已经存在,则更新当前会话;如果不存在,则创建一个新的会话并添加到会话列表,然后还需要对会话列表按一定规则进行排序,最后再通知 UI 进行刷新。
这部分的耗时为 500ms-600ms,并且随着数据量的增大耗时还会增加,所以这部分必须放到子线程中执行。但是这里必须注意线程安全问题,否则会出现数据多次被添加,会话列表上出现多条重复的数据。
4.2 增加缓存
在检查代码的时候,我们发现有很多地方会获取当前用户的信息,而当前用户信息保存在了本地 SP 中(后改为MMKV),并且以 Json 格式存储。那么在获取用户信息的时候会从 SP 中先读取出来(IO 操作),再反序列化为对象(反射)。
/**
* 获取当前用户信息
*/
public UserCacheInfo getUserCache() {
try {
String userJson = sp.getString(Const.USER_INFO, "");
if (TextUtils.isEmpty(userJson)) {
return null;
}
Gson gson = new Gson();
UserCacheInfo userCacheInfo = gson.fromJson(userJson, UserCacheInfo.class);
return userCacheInfo;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}每次都这样获取当前用户的信息会非常的耗时。为了解决这个问题,我们将第一次获取的用户信息进行缓存,如果内存中存在当前用户的信息则直接返回,并且在每次修改当前用户信息的时候,更新内存中的对象。
/**
* 获取当前用户信息
*/
public UserCacheInfo getUserCacheInfo(){
//如果当前用户信息已经存在,则直接返回
if(mUserCacheInfo != null){
return mUserCacheInfo;
}
//不存在再从SP中读取
mUserCacheInfo = getUserInfoFromSp();
if (mUserCacheInfo == null) {
mUserCacheInfo = new UserCacheInfo();
}
return mUserCacheInfo;
}
/**
* 保存用户信息
*/
public void saveUserCache(UserCacheInfo userCacheInfo) {
//更新缓存对象
mUserCacheInfo = userCacheInfo;
//将用户信息存入SP
saveUserInfo(userCacheInfo);
}4.3 减少刷新次数
在这个方案里,一方面要减少不合理的刷新,另外一方面要将部分全局刷新改为局部刷新。
在会话列表的 ViewModel 中,LiveData 订阅了数据库中用户信息表的变更、群信息表的变更、群成员表的变更。只要这三张表有变化,都会重新遍历会话列表,进行数据更新,然后通知页面刷新。逻辑看似没问题,但是却把通知页面刷新的代码写在循环当中,也就是每更新完一条会话数据,就通知页面刷新一次,如果有 100 条会话就需要刷新 100 次。
mConversationListLiveData.addSource(getAllUsers(), new Observer<List<User>>() {
@Override
public void onChanged(List<User> users) {
if (users != null && users.size() > 0) {
//遍历会话列表
Iterator<BaseUiConversation> iterable = mUiConversationList.iterator();
while (iterable.hasNext()) {
BaseUiConversation uiConversation = iterable.next();
//更新每个item上用户信息
uiConversation.onUserInfoUpdate(users);
//未优化前的代码,频繁通知页面刷新
//mConversationListLiveData.postValue(mUiConversationList);
}
mConversationListLiveData.postValue(mUiConversationList);
}
}
});将通知页面刷新的代码提取到循环外面,等待数据更新完毕以后刷新一次即可。
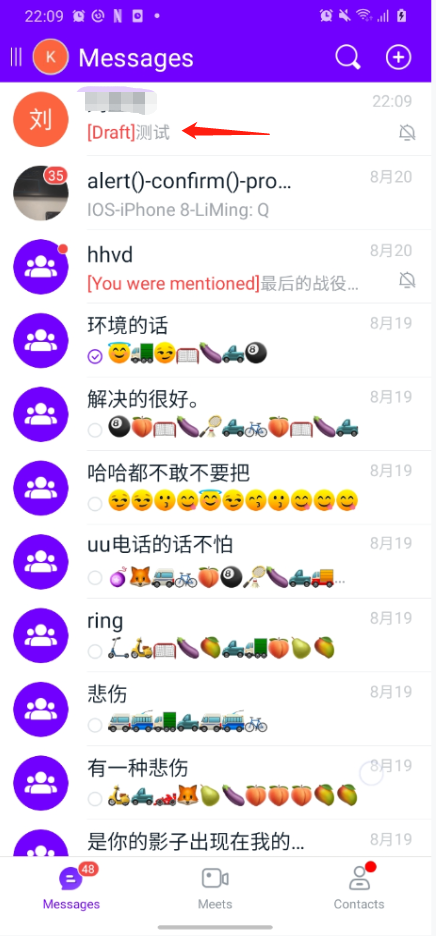
我们 APP 里面有个草稿功能,每次从会话里出来,都需要判断会话的输入框中是否存在未删除文字(草稿),如果有,则保存起来并在会话列表上显示【Draft】+内容,用户下次再进入会话后将草稿还原。由于草稿的存在,每次从会话退回到会话列表都需要刷新一下页面。在未优化之前,此处采用的是全局刷新,而我们其实只需要刷新刚刚退出的会话对应的 item 即可。
对于一款 IM 应用,提醒用户消息未读是一个常见的功能。在会话列表的用户头像上面会显示当前会话的消息未读数,当我们进入会话以后,该未读数需要清零,并且更新会话列表。在未优化之前,此处采用的也是全局刷新,这部分其实也可以改为刷新单条 item。
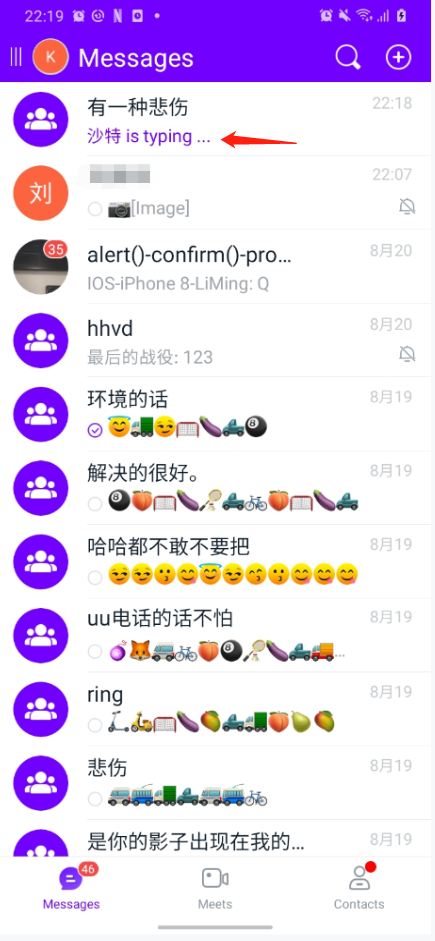
我们的 APP 新增了一个叫做 typing 的功能,只要有用户在会话里面正在输入文字,在会话列表上就会显示某某某 is typing...的文案。在未优化之前,此处也是采用列表全局刷新,如果在好几个会话中同时有人 typing,那么基本上整个会话列表就会一直处于刷新的状态。所以此处也改为了局部刷新,只刷新当前有人 typing 的会话 item。
4.4 onCreateViewHolder 优化
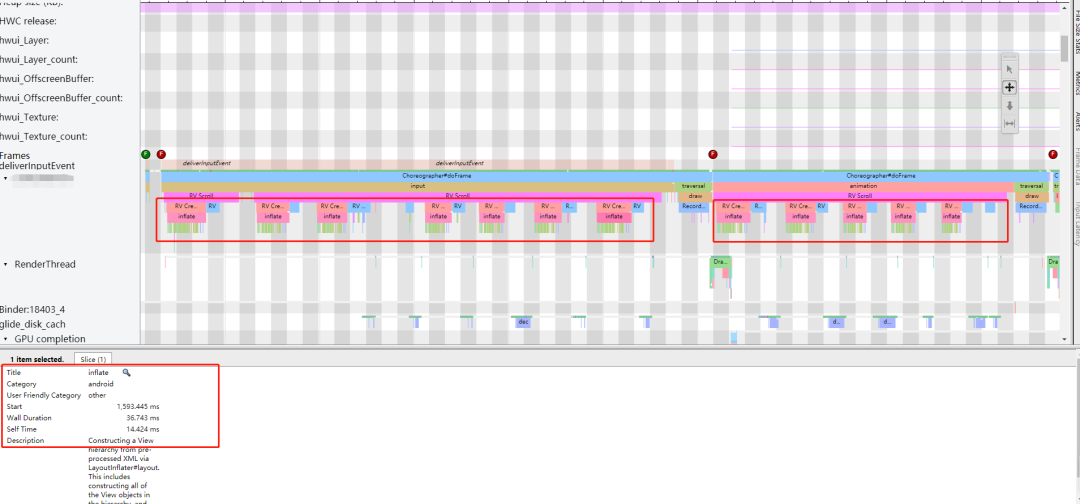
在分析 Systrace 报告时,我们发现了图中这种情况 —— 一次滑动伴随着大量的 CreateView 操作。为什么会出现这种情况呢?我们知道 RecyclerView 本身是存在缓存机制的,滑动中如果新展示的 item 布局跟老的一致,就不会再执行 CreateView,而是复用老的 item,执行 bindView 来设置数据,这样可减少创建 view 时的 IO 和反射耗时。
那么这里为什么跟预期不一样呢?我们先来看看 RecyclerView 的缓存机制。RecyclerView 有4级缓存,我们这里只分析常用的 2级:
- mCachedViews
- mRecyclerPool
mCachedViews 的默认大小为 2,当 item 刚刚被移出屏幕可视范围时,item 就会被放入 mCachedViews 中,因为用户很可能再重新将 item 移回到屏幕可视范围,所以放入 mCachedViews 中的 item 是不需要重新执行 createView 和 bindView 操作的。
mCachedViews 中采用 FIFO 原则,如果缓存数量达到最大值,那么先进入的 item 会被移出并放入到下一级缓存中。
mRecyclerPool 是 RecycledViewPool 类型,其中根据 item 类型创建对应的缓存池,每个缓存池默认大小为 5,从 mCachedViews 中移除的 item 会被清除掉数据,并根据对应的 itemType 放入到相应的缓存池中。这里有两个值得注意的地方,第一个就是 item 被清除了数据,这意味着下次使用这个 item 时需要重新执行 bindView 方法来重设数据;
另外一个就是根据 itemType 的不同,会存在多个缓存池,每个缓存池的大小默认为 5,也就是说不同类型的 item 会放入不同的缓冲池中,每次在显示新的 item 时会先找对应类型的缓存池,看里面是否有可以复用的 item,如果有则直接复用后执行 bindView,如果没有则要重新创建 view,需要执行 createView 和 bindView 操作。
Systrace 报告中出现大量的 CreateView,说明在复用 item 时出现了问题,导致每次显示新的 item 都需要重新创建。
我们来考虑一种极端场景,我们会话列表中分为 3 种类型的 item:
- 群聊 item
- 单聊 item
- 密聊 item
我们一屏能展示 10 个 item。其中前 10 个 item 都是群聊类型。从 11 个开始到 20 个都是单聊 item,从 21 个到 30 个都是密聊 item。
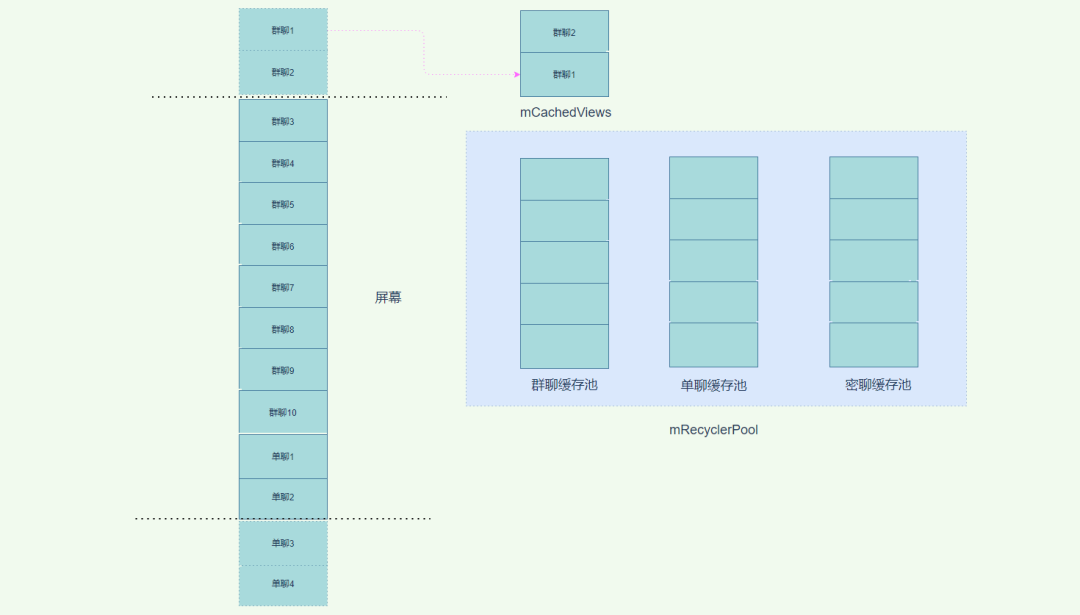
从图中我们可以看到群聊 1 和群聊 2 已经被移出了屏幕,这时候会被放入 mCachedViews 缓存中。而单聊 1 和单聊 2 因为在 mRecyclerPool 的单聊缓存池中找不到可以复用的 item,所以需要执行 CreateView 和 BindView 操作。
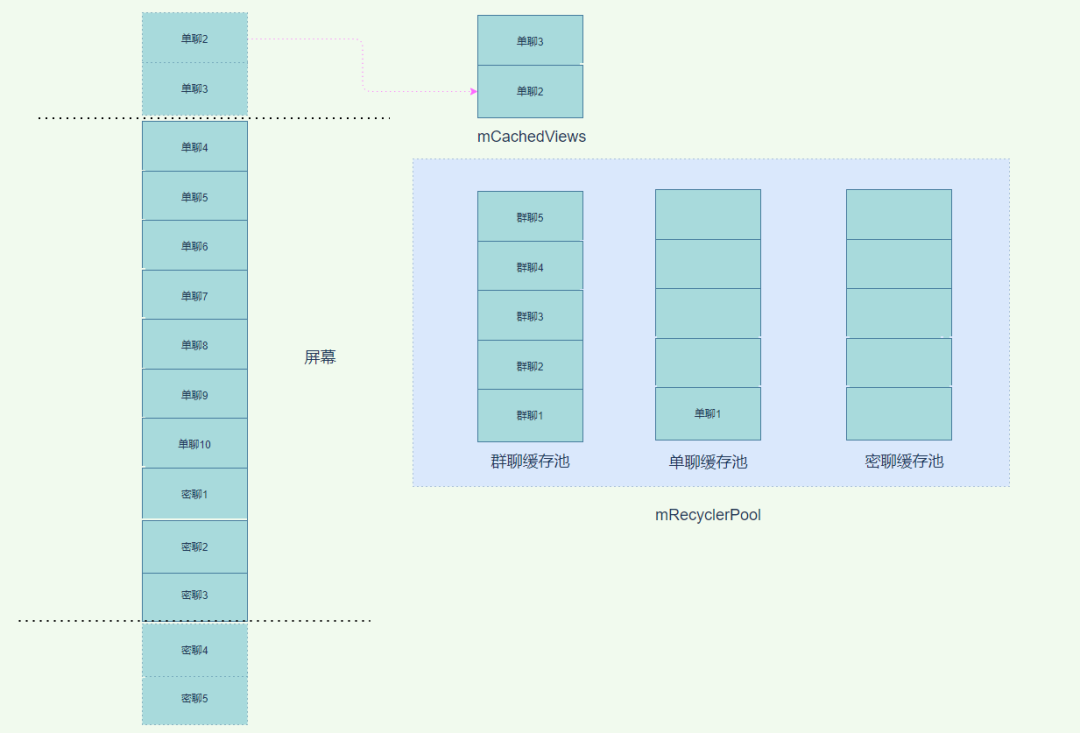
由于之前移出屏幕的都是群聊,所以单聊 item 进入时一直没用办法从单聊缓存池中拿到可以复用的 item,所以一直需要 CreateView 和 BindView。直到单聊 1 进入到缓存池,也就是上图所示,如果即将进入屏幕的是单聊 item 或者群聊 item,都是可以复用的,可惜进来的是密聊,由于密聊缓存池中没用可以复用的 item,所以接下来进入屏幕的密聊 item 也都需要执行 CreateView 和 BindView。整个 RecyclerView 的缓存机制在这种情况下,基本失效。
这里额外提一句,为什么群聊缓存池中是群聊 1 ~ 群聊 5,而不是群聊 6 ~ 群聊 10?这里不是画错了,而是 RecyclerView 判断,在缓存池满了的情况下,就不会再加入新的 item。
/**
* Add a scrap ViewHolder to the pool.
* <p>
* If the pool is already full for that ViewHolder's type, it will be immediately discarded.
*
* @param scrap ViewHolder to be added to the pool.
*/
public void putRecycledView(ViewHolder scrap) {
final int viewType = scrap.getItemViewType();
final ArrayList<ViewHolder> scrapHeap = getScrapDataForType(viewType).mScrapHeap;
//如果缓存池大于等于最大可缓存数,则返回
if (mScrap.get(viewType).mMaxScrap <= scrapHeap.size()) {
return;
}
if (DEBUG && scrapHeap.contains(scrap)) {
throw new IllegalArgumentException("this scrap item already exists");
}
scrap.resetInternal();
scrapHeap.add(scrap);
}到这里也就可以解释,为什么我们从 Systrace 报告中发现了如此多的 CreateView。知道了问题所在,那么我们就需要想办法解决。多次创建 View 主要是因为复用机制失效或者没有很好的运作导致,而失效的原因主要在于我们同时有 3 种不同的 item 类型,如果我们能将 3 种不同的 item 变为一种,那么我们就能在单聊 4 进入屏幕时,从缓存池中拿到可以复用的 item,从而省去 CreateView 的步骤,直接 BindView 重置数据。
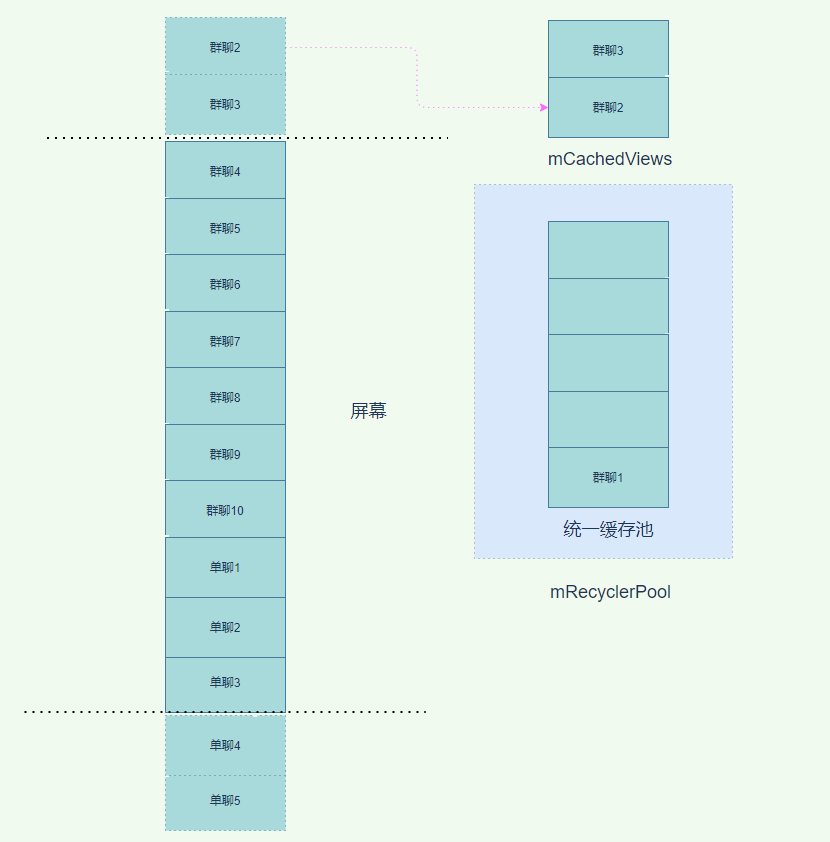
有了思路以后,我们在检查代码时发现,无论是群聊、单聊还是密聊,使用的都是同一个布局,完全可以采用同一个 itemType。以前之所以分开,是因为使用了一些设计模式,想让群聊、单聊、密聊在各自的类中实现,也方便以后如果有新的扩展会更方便清晰。这时候就需要在性能和模式上有所取舍,但是仔细一想,会话列表上面不同类型的聊天,布局基本是一致的,不同聊天类型仅仅在 UI 展示上有所不同,这些不同我们可以在 bindView 时重新设置。
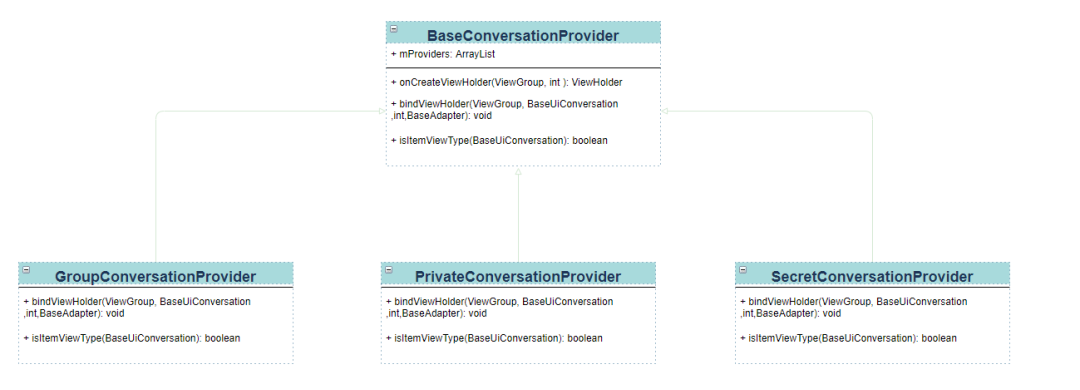
我们在注册的时候只注册 BaseConversationProvider,这样 itemType 类型就只有这一个。GroupConversationProvider、PrivateConversationProvider、SecretConversationProvider 都继承于 BaseConversationProvider 类,onCreateViewHolder 方法只在 BaseConversationProvider 类实现。在 BaseConversationProvider 类中包含一个 List,用于保存 GroupConversationProvider、PrivateConversationProvider、SecretConversationProvider 这三个对象,在执行执行 bindViewHolder 方法时,先执行父类的方法,在这里面处理一些三种聊天类型公共的逻辑,比如头像、最后一条消息发送的时间等,处理完毕以后通过 isItemViewType 判断当前是哪种聊天,并且调用相应的子类 bindViewHolder 方法,进行子类特有的数据处理。这里需要注意重用时导致的页面显示错误,比如在密聊中修改了会话标题的颜色,但是由于 item 的复用,导致群聊的会话标题颜色也改变了。
经过改造以后,我们就可以省去大量 的CreateView 操作(IO+反射),让 RecyclerView 的缓存机制可以良好的运行。
4.5 预加载+全局缓存
虽然我们减少了 CreateView 的次数,但是我们在首次进入时第一屏还是需要 CreateView,并且我们发现 CreateView 的耗时也挺长。
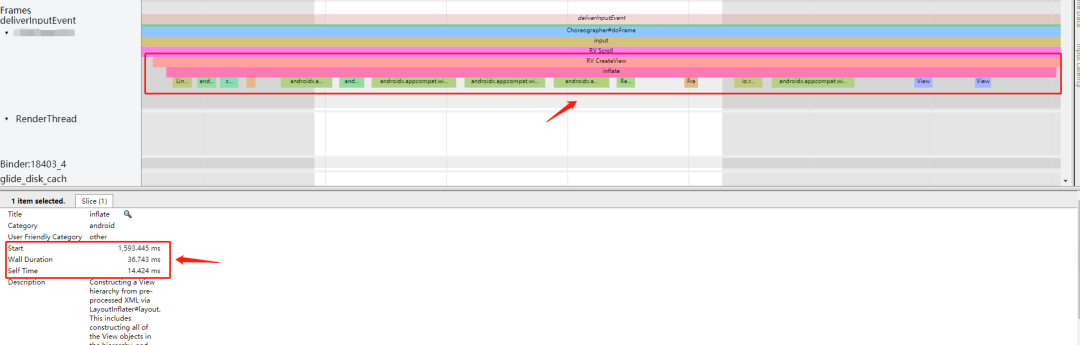
这部分时间能不能优化掉?我们首先想到的是在 onCreateViewHolder 时采用异步加载布局的方式,将 IO、反射放在子线程来做,后来这个方案被去掉了,具体原因后文会说。如果不能异步加载,那么我们就考虑将创建 View 的操作提前来执行并且缓存下来。
我们首先创建了一个 ConversationItemPool 类,该类用于在子线程中预加载 item,并且将它们缓存起来。当执行 onCreateViewHolder 时直接从该类中获取缓存的 item,这样就可以减少 onCreateViewHolder 执行耗时。
/**
* Add a scrap ViewHolder to the pool.
* <p>
* If the pool is already full for that ViewHolder's type, it will be immediately discarded.
*
* @param scrap ViewHolder to be added to the pool.
*/
public void putRecycledView(ViewHolder scrap) {
final int viewType = scrap.getItemViewType();
final ArrayList<ViewHolder> scrapHeap = getScrapDataForType(viewType).mScrapHeap;
//如果缓存池大于等于最大可缓存数,则返回
if (mScrap.get(viewType).mMaxScrap <= scrapHeap.size()) {
return;
}
if (DEBUG && scrapHeap.contains(scrap)) {
throw new IllegalArgumentException("this scrap item already exists");
}
scrap.resetInternal();
scrapHeap.add(scrap);
}ConversationItemPool 中我们使用了一个线程安全队列来缓存创建的 item。由于是全局缓存,所以这里要注意内存泄漏的问题。那么我们预加载多少个 item 合适呢?经过我们对不同分辨率测试机的对比,首屏展示的 item 数量一般为 10-12 个,由于在第一次滑动时,前 3 个 item 是拿不到缓存的,也需要执行 CreateView 方法,那么我们还需要把这 3 个也算上,所以我们这边设置预加载数量为 16 个。之后在 onViewDetachedFromWindow 方法中将 View 进行回收再次放入缓存池。
@Override
public ViewHolder onCreateViewHolder(ViewGroup parent, int viewType) {
//从缓存池中取item
View view = ConversationListItemPool.getInstance().getItemFromPool();
//如果没取到,正常创建Item
if(view == null) {
view = LayoutInflater.from(parent.getContext()).inflate(R.layout.rc_conversationlist_item,parent,false);
}
return ViewHolder.createViewHolder(parent.getContext(), view);
}注意在 onCreateViewHolder 方法中要有降级操作,万一没取到缓存 View,需要正常创建一个使用。这样我们成功地将 onCreateViewHolder 的耗时降低到了 2 毫秒甚至更低,在 RecyclerView 缓存生效时,可以做到 0 耗时。
解决从 XML 创建 View 耗时的方案,除了在异步线程中预加载,还可以使用一些开源库比如 X2C 框架,主要原理就是在编译期间将 XML 文件转换为 JAVA 代码来创建 View,省去 IO 和反射的时间。或者使用 jetpack compose 声明式 UI 来构建布局。
4.6 onBindViewHolder 优化
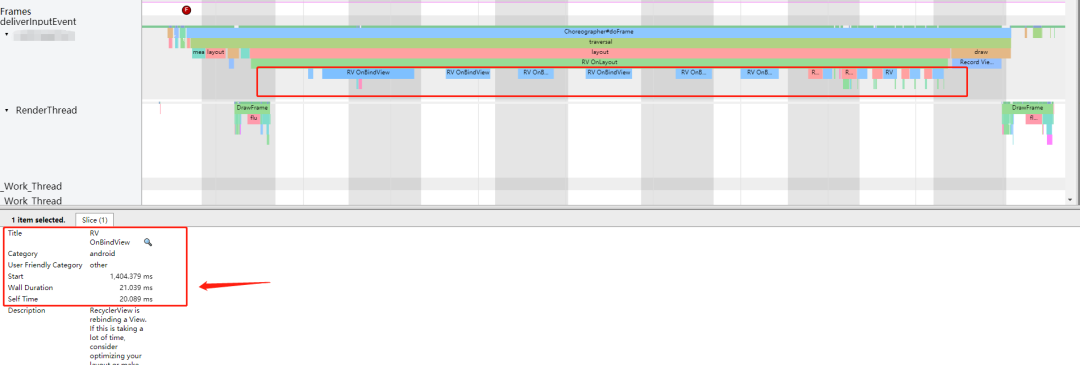
我们在查看 Systrace 报告时,还发现,除了 CreateView 耗时,BindView 竟然也很耗时,而且这个耗时甚至超过了 CreateView。这样在一次滑动过程中,如果有 10 个 item 新展示出来,那么耗时将达到 100 毫秒以上。这是绝对不能接受的,于是我们开始清理 onBindViewHolder 的耗时操作。
首先我们必须清楚 onBindViewHolder 方法中只用于 UI 设置,不应该做任何的耗时操作和业务逻辑处理,我们需要把耗时操作和业务处理提前处理好,存入数据源中。
我们在检查 onBindViewHolder 方法时发现,如果用户头像不存在,会再生成一个默认的头像,该头像会以用户名首字母来生成。在该方法中,首先进行了 MD5 加密,然后创建 Bitmap,再压缩,再存入本地(IO)。这一系列操作非常的耗时,所以我们决定把该操作从 onBindViewHolder 中提取出来,提前将生成数据放入数据源,用的时候直接从数据源中获取。
我们的会话列表上面,每条会话都需要显示最后一条消息的发送时间,时间显示格式非常复杂,每次在 onBindViewHolder 中都会将最后一条消息的毫秒数格式化成相应的 String 来显示。这部分也非常耗时,我们把这部分的代码也提取出来处理,在 onBindViewHolder 中只需要从数据源中取出格式化好的字符串显示即可。
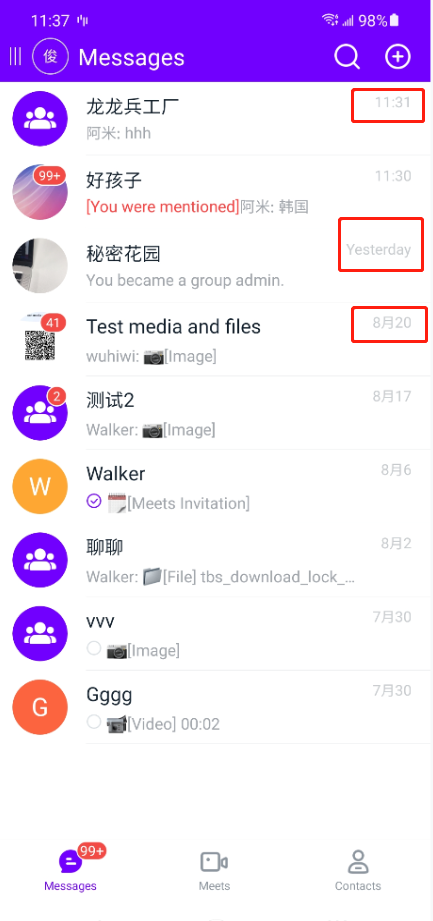
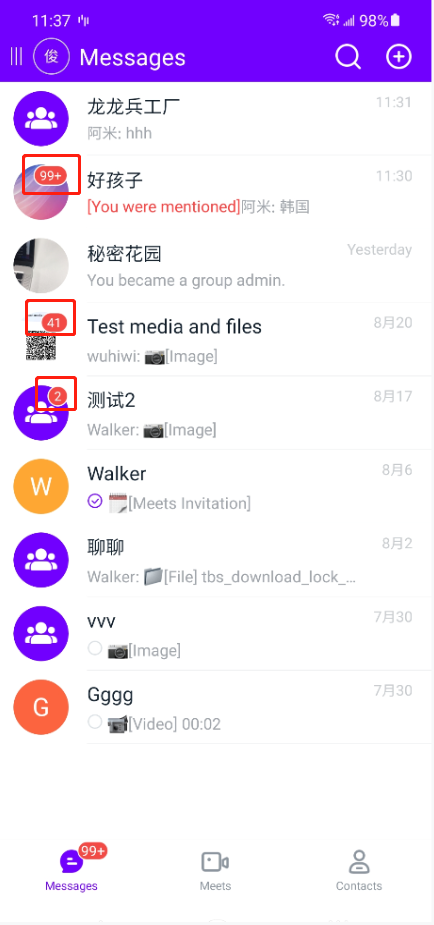
在我们的头像上面会显示当前未读消息数量,但是这个未读消息数有几种不同的情况:
- 未读消息数是个位数,则背景图是圆的;
- 未读消息数是两位数,背景图是椭圆;
- 未读消息数大于 99,显示 99+,背景图会更长;
- 该消息被屏蔽,只显示一个小圆点,不显示数量。
如下图:
由于存在这几种情况,此处的代码直接根据未读消息数,设置了不同的 png 背景图片。这部分的背景其实完全可以采用 Shape 来实现。如果使用 PNG 图片的话,需要对 png 进行解码,然后再由 GPU 渲染,图片解码会消耗 CPU 资源。而 Shape 信息会直接传到底层由 GPU 渲染,速度更快。所以我们将 png 图片替换为 Shape 实现。
除了图片的设置,在 onBindViewHolder 中用的最多的就是 TextView,TextView 在文本测量上花费的时间占文本设置的很大比例,这部分测量的时间其实是可以放在子线程中执行的,Android 官方也意识到了这点,所以在 Android P 推出了一个新的类:PrecomputedText,该类可以让最耗时的文本测量在子线程中执行。由于该类是 Android P 才有,所以我们可以使用 AppCompatTextView 来代替 TextView,在 AppCompatTextView 中做了版本兼容性处理。
AppCompatTextView tv = (AppCompatTextView) view;
//用这个方法代替setText
tv.setTextFuture(PrecomputedTextCompat.getTextFuture(text,tv.getTextMetricsParamsCompat(),
ThreadManager.getInstance().getTextExecutor()));使用起来很简单,原理这里就不赘述了,可以自行谷歌。在低版本中还使用了 StaticLayout 来进行渲染,可以加快速度,具体可以看 Instagram 的一篇文章
4.7 布局优化
除了减少 BindView 的耗时以外,布局的层级也影响着 onMeasure 和 onLayout 的耗时。我们在使用 GPU 呈现模式分析工具时发现测量和布局花费了大量的时间,所以我们打算减少 item 的布局层级。
在未优化之前,我们 item 布局的最大层级为 5。其实有些只是为了控制显隐方便而多增加了一层布局来包裹,我们最后使用约束布局,将最大层级降低到了 2 层。
除此之外我们还检查了是否存在重复设置背景颜色的情况,因为重复设置背景颜色会导致过度绘制。所谓过度绘制指的是某个像素在同一帧内被绘制了多次。如果不可见的 UI 也在做绘制操作,这会导致某些区域的像素被绘制了多次,浪费大量的 CPU、GPU 资源。
除了去掉重复的背景,我们还可以尽量减少使用透明度,Android 系统在绘制透明度时会将同一个区域绘制两次,第一次是原有的内容,第二次是新加的透明度效果。基本上 Android 中的透明度动画都会造成过度绘制,所以可以尽量减少使用透明度动画,在 View 上面也尽量不要使用 alpha 属性。具体原理可以参考谷歌官方视频。
在使用约束布局来减少层级,并且去掉重复背景以后,我们发现还是会有点卡。在网上查阅相关资料,发现也有网友反馈在 RecyclerView 的 item 中使用约束布局会有卡顿的问题,应该是约束布局的 Bug 导致,我们也检查了一下我们使用的约束布局版本号。

用的是 beta 版本,我们改为最新稳定版 2.1.0。发现情况好了很多。所以商业应用尽量不要使用测试版本。
4.8 其他优化
除了上面所说的优化点,还有一些小的优化点:
(1)比如使用高版本的 RecyclerView,会默认开启预取功能。
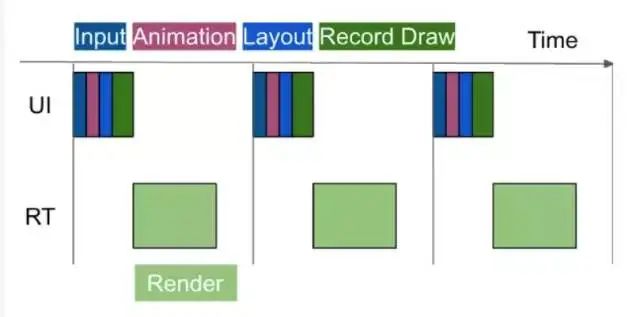
从上图中我们可以看见,UI 线程完成数据处理交给 Render 线程以后就一直处于空闲状态,需要等待个 Vsync 信号的到来才会进行数据处理,而这空闲时间就被白白浪费了,开启预取以后就能合理地使用这段空闲时间。

(2)将 RecyclerView 的 setHasFixedSize 方法设置为 true。当我们的 item 宽高固定时,使用 Adapter 的 onItemRangeChanged()、onItemRangeInserted()、onItemRangeRemoved()、
onItemRangeMoved() 这几个方法更新 UI,不会重新计算大小。
(3)如果不使用 RecyclerView 的动画,可以通过 ((SimpleItemAnimator) rv.getItemAnimator()).setSupportsChangeAnimations(false) 把默认动画关闭来提升效率。
五、弃用的方案
在做会话列表卡顿优化过程中,我们采用了一些优化方案,但是最终没有采用,这里也列出加以说明。
5.1 异步加载布局
在前文中有提到,我们在减少 CreateView 耗时的过程中,最初打算采用异步加载布局的方式来将 IO、反射放在子线程中执行。我们使用的是谷歌官方的 AsyncLayoutInflater 来异步加载布局,该类会将布局加载完成以后回调通知我们。但是它一般用于 onCreate 方法中。而在 onCreateViewHolder 方法中需要返回 ViewHolder,所以没有办法直接使用。
为了解决这个问题,我们自定义了一个 AsyncFrameLayout 类,该类继承于 FrameLayout,我们会在 onCreateViewHolder 方法中将 AsyncFrameLayout 作为 ViewHolder 的根布局添加进去,并且调用自定义的 inflate 方法,进行异步加载布局,加载成功以后再把加载成功的布局添加到 AsyncFrameLayout 中,作为 AsyncFrameLayout 的子 View。
public void inflate(int layoutId, OnInflateCompleted listener) {
new AsyncLayoutInflater(getContext()).inflate(layoutId, this, new AsyncLayoutInflater.OnInflateFinishedListener() {
@Override
public void onInflateFinished(@NonNull @NotNull View view, int resid, @Nullable @org.jetbrains.annotations.Nullable ViewGroup parent) {
//标记已经inflate完成
isInflated = true;
//加载完布局以后,添加为AsyncFrameLayout中
parent.addView(view);
if (listener != null) {
//加载完数据后,需要重新请求BindView绑定数据
listener.onCompleted(mBindRequest);
}
mBindRequest = null;
}
});
}这里注意,因为是异步执行,所以在 onCreateViewHolder 执行完成以后,会执行 onBinderViewHolder 方法,而这时候布局是很有可能没有加载完成的,所以需要用一个标志为 isInflated 来标识布局是否加载成功,如果没有加载完成,就先不绑定数据。同时要记录本次 BindView 请求,当布局加载完成以后,主动地调用一次去刷新数据。
没有采用此方法的主要原因在于会增加布局层级,在使用预加载以后,可以不使用此方案。
5.2 DiffUtil
DiffUtil 是谷歌官方提供的一个数据对比工具,它可以对比两组新老数据,找出其中的差异,然后通知 RecyclerView 进行刷新。DiffUtil 使用 Eugene W. Myers 的差分算法来计算将一个列表转换为另一个列表的最少更新次数。但是对比数据时也会耗时,所以也可以采用 AsyncListDiffer 类,把对比操作放在异步线程中执行。
在使用 DiffUtil 中我们发现,要对比的数据项太多了,为了解决这个问题,我们对数据源进行了封装,在数据源里添加了一个表示是否更新的字段,把所有变量改为 private 类型,并且提供 set 方法,在 set 方法中统一将是否更新的字段设置为 true。这样在进行两组数据对比时,我们只需要判断该字段是否为 true,就知道是否存在更新。
想法是美好的,但是在实际封装数据源时发现,类中还有类(也就是类中有对象,不是基本数据类型),外部完全可以通过先 get 到一个对象,然后通过改对象的引用修改其中的字段,这样就跳过了 set 方法。如果要解决这个问题,那么我们需要在封装类中提供类中类属性的所有 set 方法,并且不提供类中类的 get 方法,改动非常的大。
如果仅仅是这个问题,还可以解决,但是我们发现会话列表上面有一个功能,就是每当其中一个会话收到了新消息,那么该会话会移动到会话列表的第一位。由于位置发生了改变,整个列表都需要刷新一次,这就违背了使用 DiffUtil 进行局部刷新的初衷了。比如会话列表第五个会话收到了新消息,这时第五个会话需要移动到第一个会话,如果不刷新整个列表,就会出现重复会话的问题。由于这个问题的存在,我们弃用了 DiffUtil,因为就算解决了重复会话的问题,收益依然不会很大。
5.3 滑动停止时刷新
为了避免会话列表大量刷新操作,我们将会话列表滑动时的数据更新给记录了下来,等待滑动停止以后再进行刷新。但是在实际测试过程中,停止后的刷新会导致界面卡顿一次,中低端机上比较明显,所以放弃了此策略。
5.4 提前分页加载
由于会话列表数量可能很多,所以我们采用分页的方式来加载数据。为了保证用户感知不到加载等待的时间,我们打算在用户将要滑动到列表结束位置之前获取更多的数据,让用户无痕地下滑。想法是理想的,但是实践过程中也发现在中低端机上会有一瞬间的卡顿,所以该方法也暂时先弃用。
除了以上方案被弃用了,我们在优化过程中发现,其它品牌相似产品的会话列表滑动其实速度并没特别快,如果滑动速度慢的话,那么在一次滑动过程中需要展示的 item 数量就会小,这样一次滑动就不需要渲染过多的数据。这其实也是一个优化点,后面我们可能会考虑降低滑动速度的实践。
六、成果
以下分别为优化前(左)和优化后(右)效果。
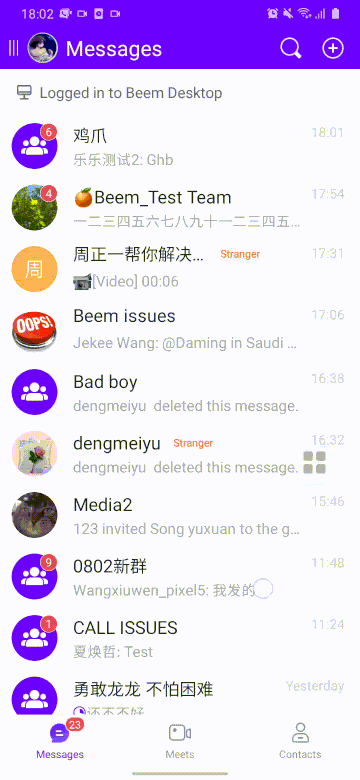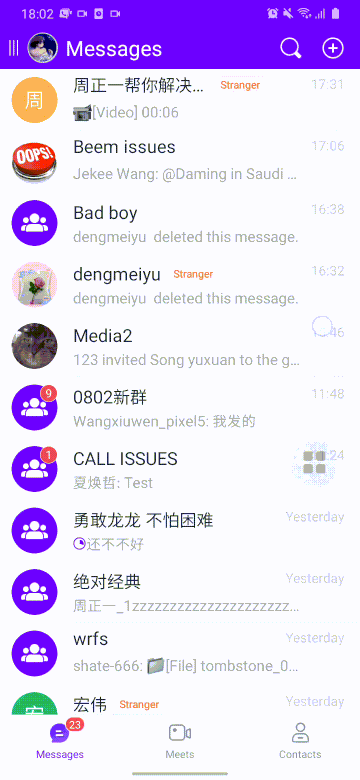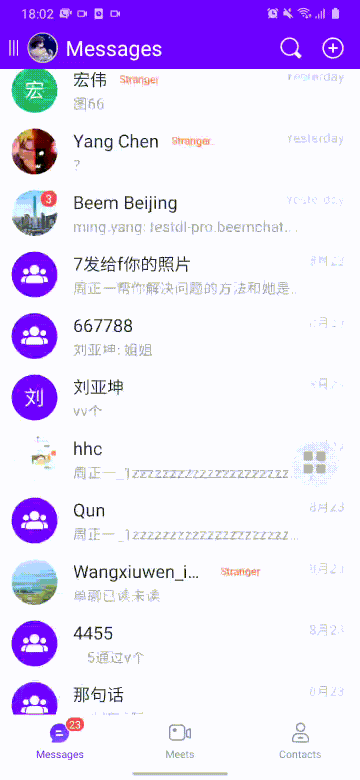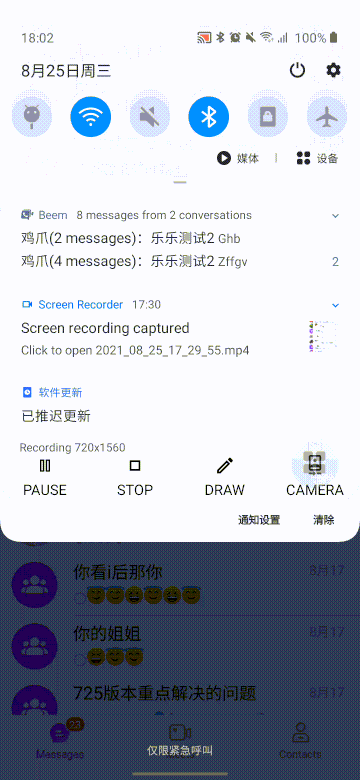
七、总结
在开发过程中,随着业务的不断新增,我们的方法和逻辑复杂度也会不断增加,这时候一定要注意方法耗时,耗时严重的尽量提取到子线程中执行。使用 Recyclerview 时千万不要无脑刷新,能局部刷的绝不全局刷,能延迟刷的绝不马上刷。在分析卡顿的时候可以结合工具进行,这样效率会提高很多,通过 Systrace 发现大概的问题和排查方向以后,可以通过 Android Studio 自带的 Profiler 来进行具体代码的定位。