QCon 主题演讲:AI 算法在视频可分级编码中的应用
上周,我们整理了融云流媒体架构师许杰在 10 月 21 日 QCon 中的精彩分享《实时通信全链路质量追踪与指标体系构建》。本周将继续放送 QCon 专场议题 —— 由融云视频算法专家黄博士带来的分享《AI 算法在视频可分级编码(SVC)中的应用》。
主要包括五部分内容:三种常用的可分级视频编码的特点;WebRTC 采用的编码器及其应用方式;可分级编码在 WebRTC 中的应用现状;基于可分级编码的目标检测和码率分配方式;AI 和可分级编码结合的应用前景和研究方向。
三种常用 可分级视频编码的特点
视频图像经过数字化之后数据量非常大,现有的网络和存储设备无法直接存储原始的视频图像,必须对视频和图像进行压缩,现有的主流压缩视频算法为 H.264,VP8,VP9,HEVC,VVC 等。一方面,从 H.264 到 VVC,编码复杂度越来越高,压缩效率也越来越高;另一方面,传输的网络带宽大小不一,且随时变化,单一的码流无法适应多种不同接收端的网络和设备环境。比如 4G 网络和 5G 网络传输带宽不一样,若在 4G 和 5G 网络中传输同一套码流,有可能会导致 5G 网络带宽没有充分利用,最终影响视频的观看效果。
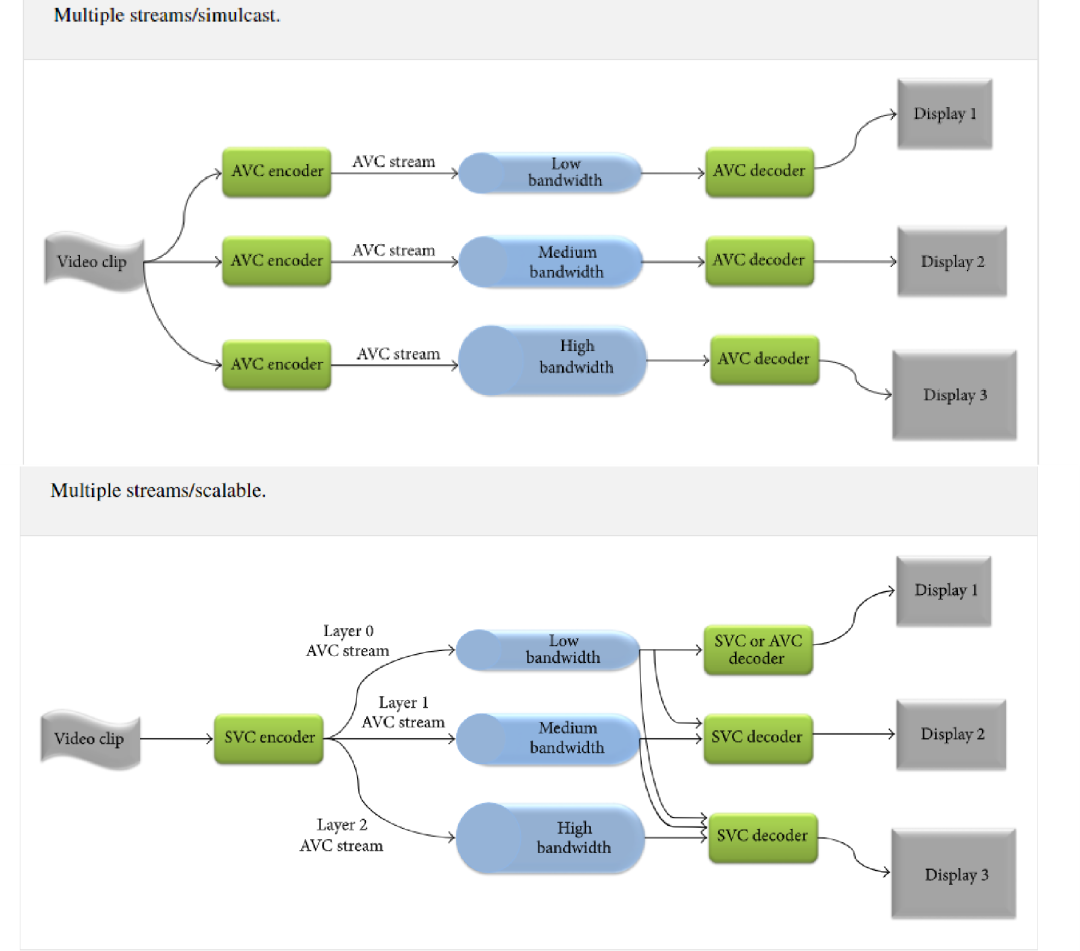
现在视频应用的环境存在多个不同的接收端,解决这个问题可以采用以下两种技术:联播(Simulcast)和可分级视频编码(SVC)。
如图 1 所示,联播 Simulcast 即同时传输多路码流,不同的码流具有不同的码率,用以传输在不同带宽下的码流。当终端设备处于高带宽的网络环境中,可以传输高码率的视频,以便获得更好的视频观看体验;当终端设备处于低带宽的网络环境中,可以传输低码率的视频,以便减少视频播放卡顿的现象。但是 Simulcast 支持的码率种类是有限的,难以适应复杂的网络环境。针对这个问题,研究人员提出了可分级视频编码 SVC,视频数据只压缩一次,却能以多个帧率、空间分辨率或视频质量进行解码。比如采用三层空域可分级和两层时域可分级,可以组合的模式达到六种,和 Simulcast 方式相比,系统的适应性得到很大提升。
常用的可分级编码有三种,分别是:空域可分级(Spatial Scalability)、质量可分级(Quality Scalability)和时域可分级(Temporal Scalability)。

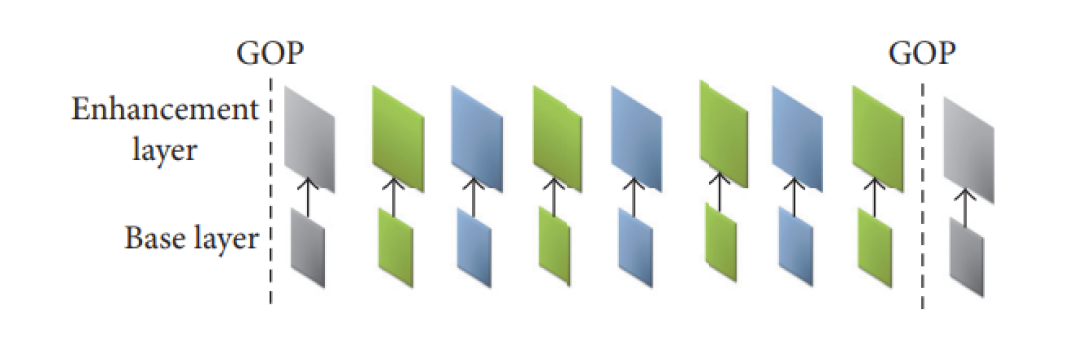
空域可分级编码(图 3 ),即对视频中的每帧图像产生多个不同空间分辨率的图像,解码基本层码流得到的低分辨率图像,如果加入增强层码流到解码器,得到的是高分辨率图像。
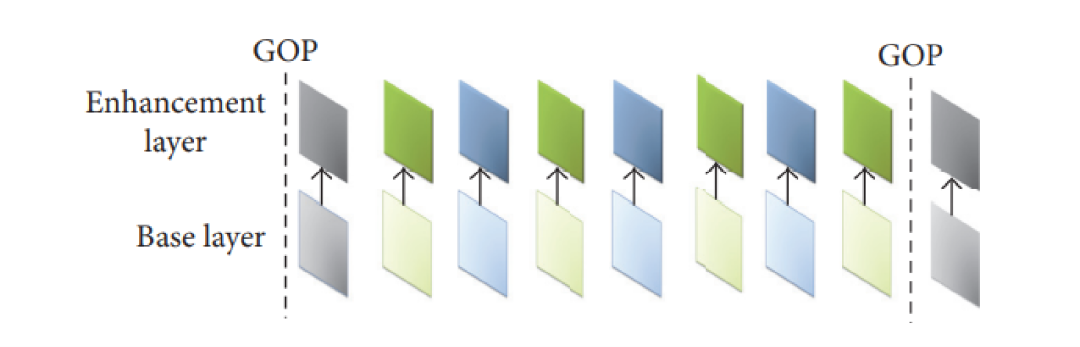
质量可分级(图 4 ),一个可行的做法是,基本层码流编码这一路对原始图像 DCT 变换后进行一次粗糙量化,熵编码后形成基本层码流。粗糙量化后的数据经反量化后形成基本层系数,与原始图像 DCT 变换系数相减形成差值信号,再对此差值信号再进行一次细量化和熵编码生成增强层码流。
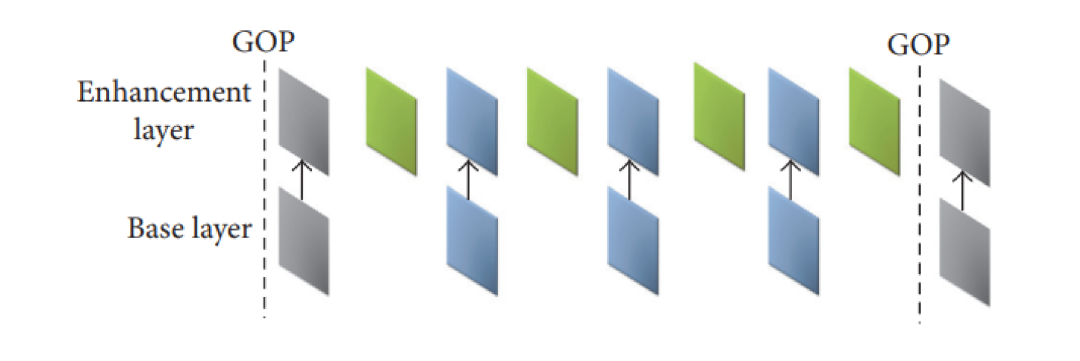
时域可分级(图 5),即把视频序列不重叠地分割成多层,对基本层的帧进行普通的视频编码,提供具有基本时间分辨率的基本层码流;对增强层则是利用基本层数据对增强层的帧间预测编码,生成增强层数据。
WebRTC 采用的 编码器及其应用方式
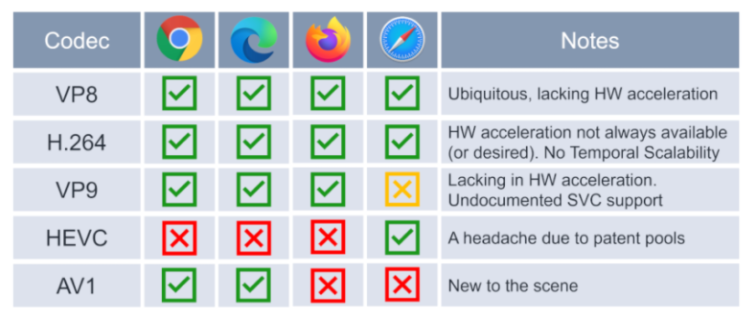
WebRTC 支持的编码器包括 VP8,VP9 和 H.264。在用户感受层面, VP8 和 H.264 两种编码器的效果基本上是类似的。VP9 作为 VP8 的下一代编码器,在高清视频压缩方面,比 VP8 和 H.264 效果要好。
如图 6,综合编码器性能和浏览器编码器的支持情况,可以得出如下结论:VP8 和 H.264编码效果基本一致,一般情况下两者皆可;VP9 主要用在 Google 公司自己的各种视频产品中,其中需要特别指出的是,VP9 支持多种 SVC ;HEVC 目前只能在苹果系统中使用,无法推广,不建议使用;AV1 同样太新了,仅仅在 Google 公司的产品中才能很好地支持,暂时不推荐。
可分级编码 在 WebRTC 中的应用现状
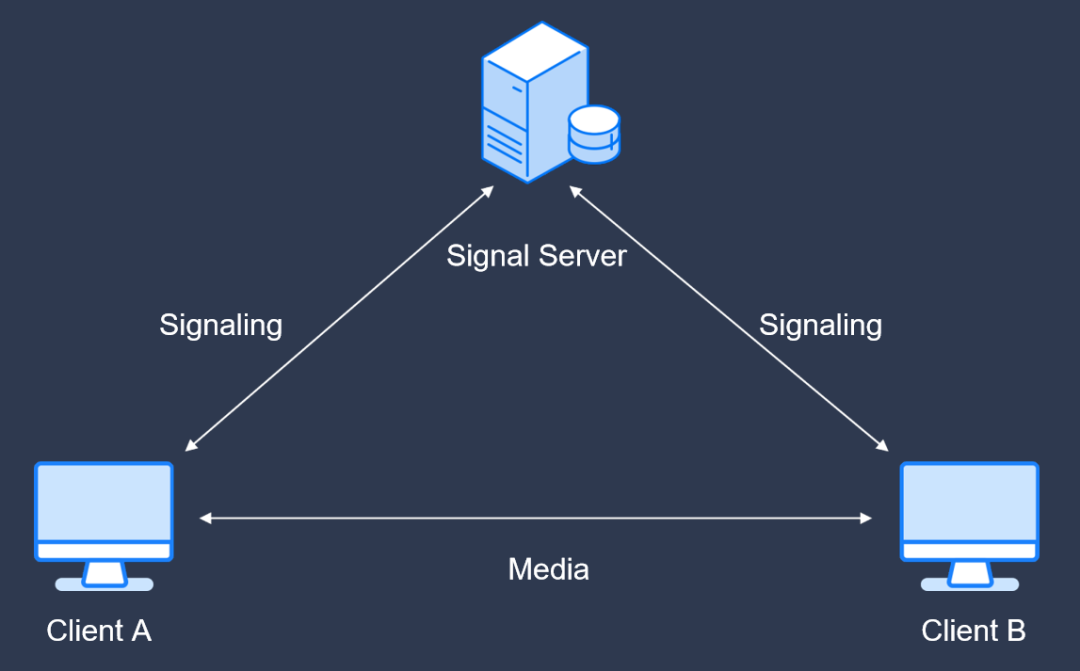
在介绍可分级编码在 WebRTC 中的应用情况之前,先简要介绍下 WebRTC 的通信和组网流程。
如图 7,客户端 A 和客户端 B 通信,可以采用直连的模式,也可以采用服务器的模式,在大规模的网络中,都会采用基于服务器的模式进行转发、信号处理等。
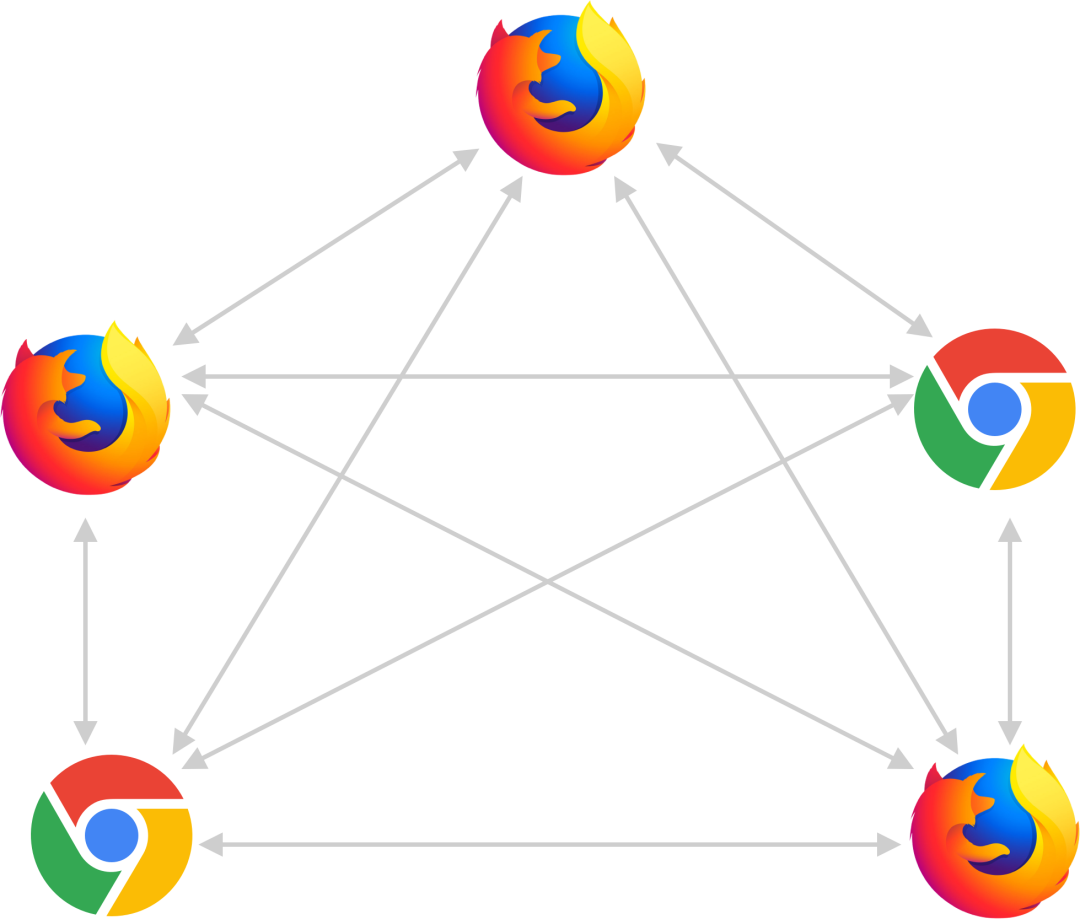
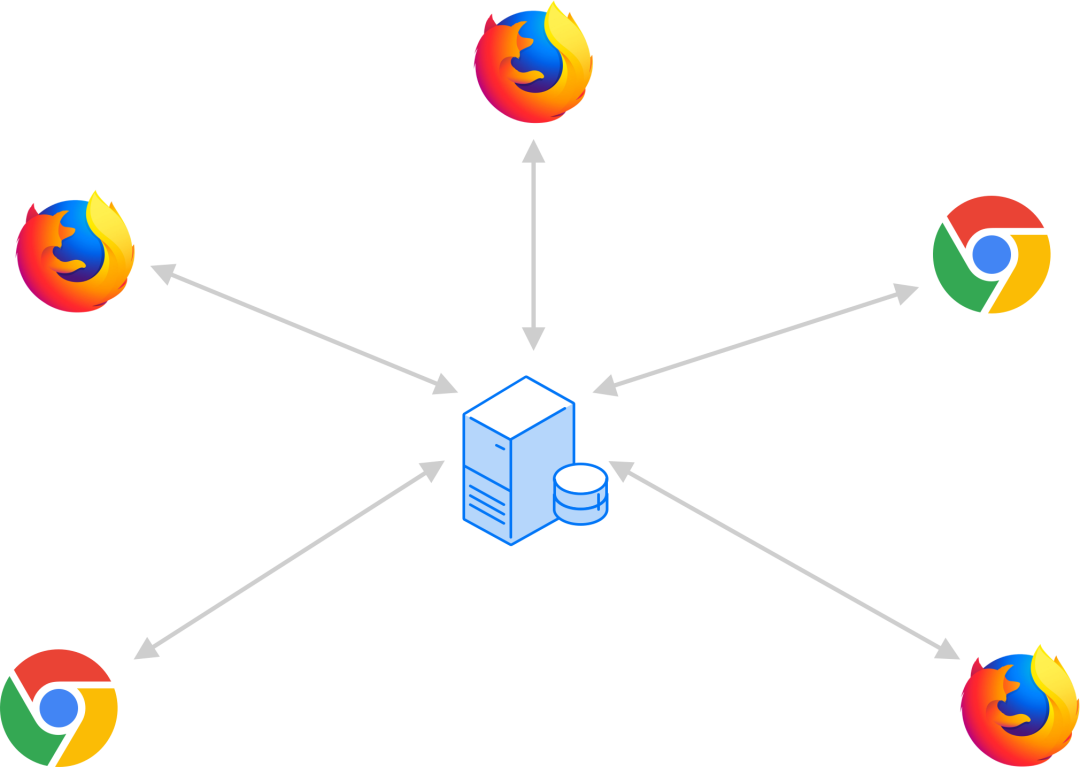
针对多种应用场景具有多个接收端的特点,WebRTC 提供了三种解决方案:Mesh,MCU,SFU。
Mesh 方案(图 8),即多个终端之间两两进行连接,形成一个网状结构。比如 A、B、C 三个终端进行多对多通信,当 A 想要共享媒体(如音频、视频)时,它需要分别向 B 和 C 发送数据。同样的道理,B 想要共享媒体,就需要分别向 A、C 发送数据,依此类推。这种方案对各终端的带宽要求比较高。
MCU(Multipoint Conferencing Unit)方案(图 9),该方案由一个服务器和多个终端组成一个星形结构。各终端将自己要共享的音视频流发送给服务器,服务器端会将在同一个房间中的所有终端的音视频流进行混合,最终生成一个混合后的音视频流再发给各个终端,这样各终端就可以看到/听到其他终端的音视频了。实际上服务器端就是一个音视频混合器,这种方案服务器的压力会非常大。
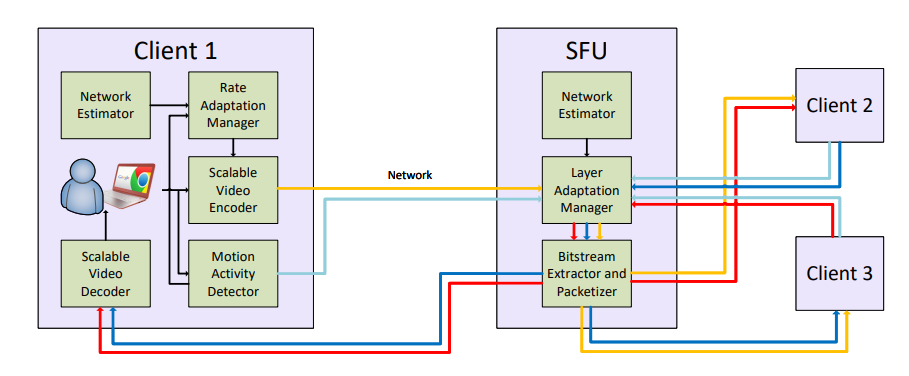
SFU(Selective Forwarding Unit)方案(图 10),该方案也是由一个服务器和多个终端组成,但与 MCU 不同的是,SFU 不对音视频进行混流,收到某个终端共享的音视频流后,就直接将该音视频流转发给房间内的其他终端。
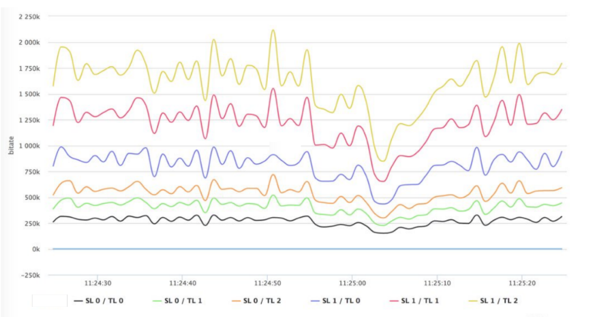
三种网络不同的带宽如图 11 所示。可以看出,SFU 的带宽最大达到了 25mbps,MCU 最小 10mbps。
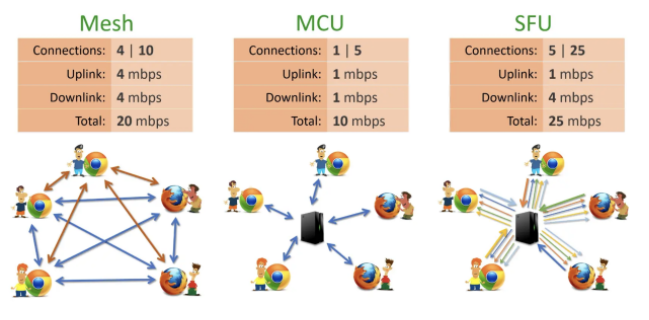
在特点方面,Mesh 方案的灵活性比较差;MCU 方案需要对码流进行类似转码、合流、分流等操作;SFU 方案服务器的压力小,灵活性更好,受到广泛欢迎。
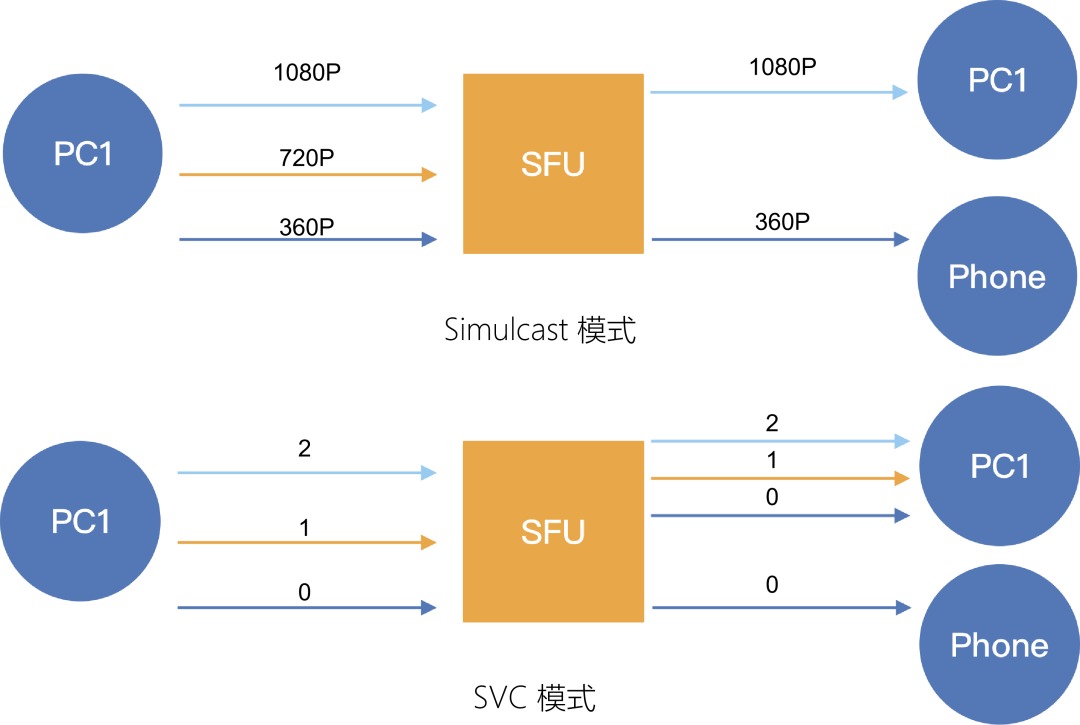
如图 12 为 Simulcast 模式和 SVC 模式转发方式示意图。从上下两个图可以看出,采用基于 SVC 的码流分配方式,对于 PC 端而言,具有更大的可修改性。无论采用哪种组网方式,采用 SVC 的方式,都会比采用 Simulcast 的方式具有更好的健壮性。
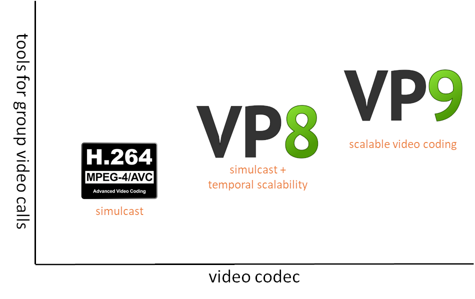
支持情况如图 13 所示。从图中可以看出,H.264 仅支持 Simulcast,VP8 支持时域可分级,VP9 则全方位支持 SVC 编码。VP9 是 Google 公司在主推的编解码器,但是在 H.264 编解码器优化方面的推进力度不大,一定程度上限制了 WebRTC 的应用,比如苹果公司最新出品的 iPhone13 手机自带 H.264 的硬件加速功能,如果采用 AV1 编码器,虽然可以获得 SVC 的优点,但是无法进行硬件解码。在 WebRTC 中,Simulcast 是默认通过多线程技术,同时启动多个 OpenH264 编码器, SVC 则是可以调用 OpenH264 进行时域和空域可分级编码。
基于可分级 编码的目标检测和码率分配方案
对于 N 路的 SFU 而言,SFU 必须考虑剩余 N-1 个终端码率总和。对于大多数视频会议而言,在给定的时域和空域层条件下的码率和总码率比例基本恒定。如图 14 所示。
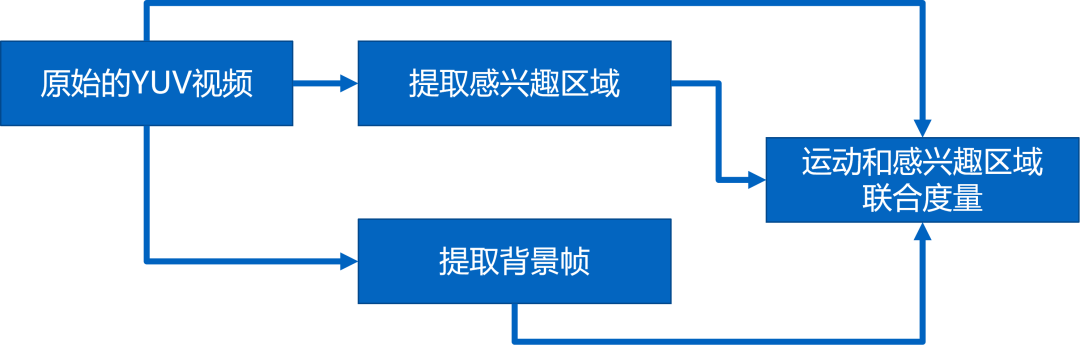
根据图 14 的现象,将视频运动作为一个主要是衡量指标,对码流进行分配。相关论文具体的方案框架如图 15 所示。
该方案存在两个改进空间:第一个是运动量度的方法采用的当前帧和前一帧的差,难以准确地反映出视频运动变化的情况。第二个是增加除了运动特征以外的其他特征,以便更好地反映图像视频的变化。拟采用的解决方案如图 16 所示。
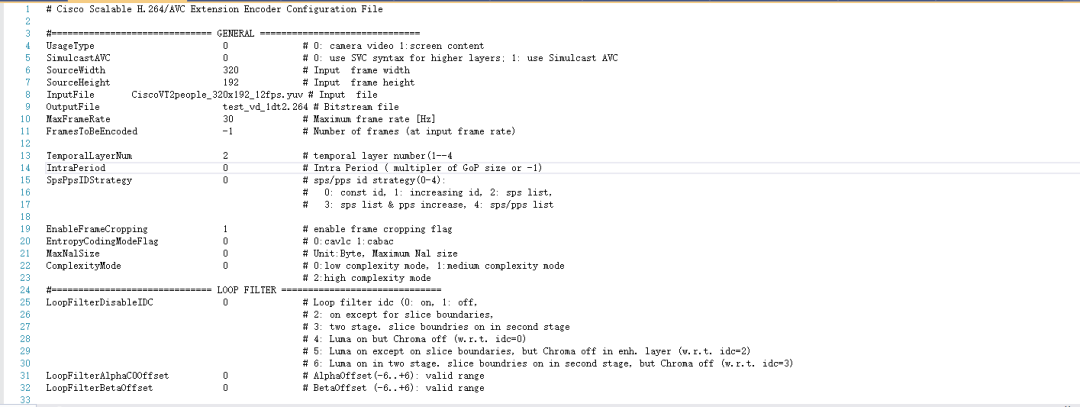
在 WebRTC 中,H.264 的编码器采用思科公司开源的 OpenH264 编码器,OpenH264 可分级编码配置文件展示如下。这个配置文件设置了时域分级层两层。
SVC 码流的特点是一套码流具有多层结构,在实际使用中,需要对码流进行提取操作。对于时域可分级而言,通过分析每个 NAL 中的 Temporal ID 对码流进行提取;对于空域可分级而言,通过分析每个 NAL 中的 Spatial ID 对码流进行提取;对于质量可分级而言,通过分析每个 NAL 中的 Quality ID 对码流进行提取。
从图 18 中可以看出,OpenH264 的基本层的码流可以直接采用 AVC 解码器解码,基本层的 SVC_extension_flag 等于1。
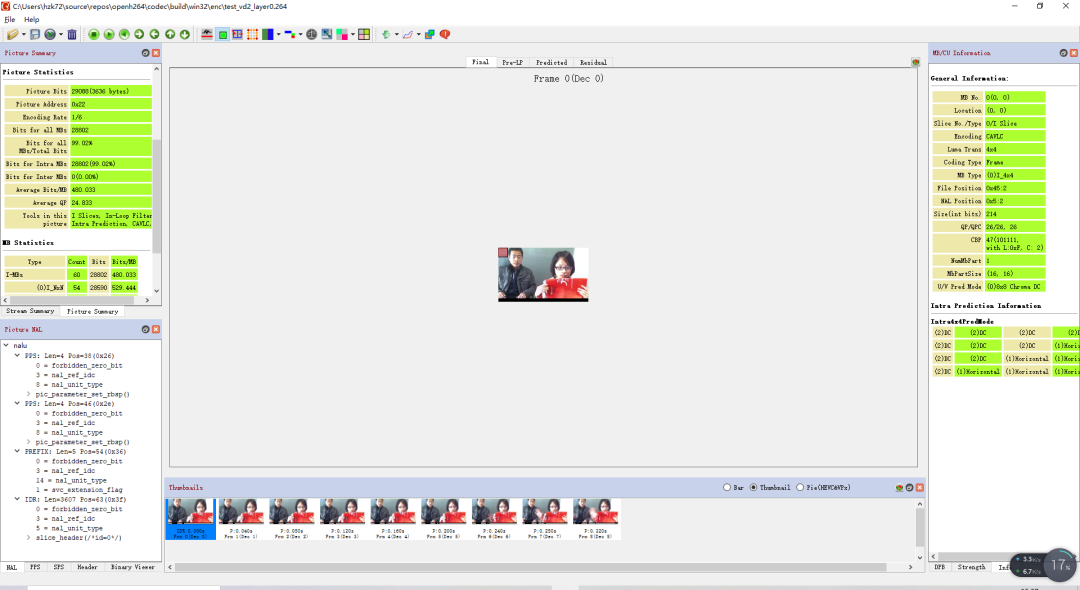
SVC 增强层码流的 NAL 包含 SVC 的语法,需要对 SVC 的码流进行转码,可分级编码的参考软件 JSVM 中有专门的转码模块,图 19 为转码过程,可以发现多个 NAL 单元被重写成 AVC 的格式。
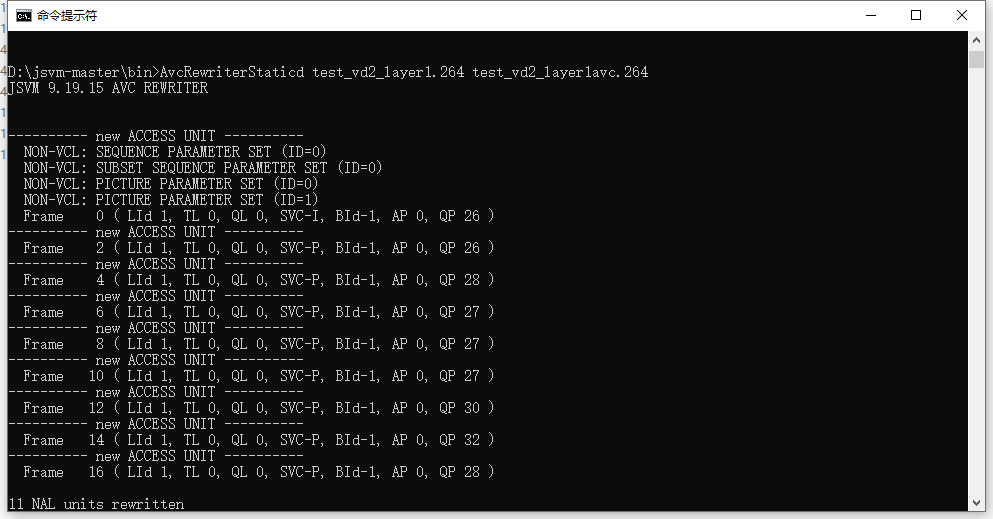
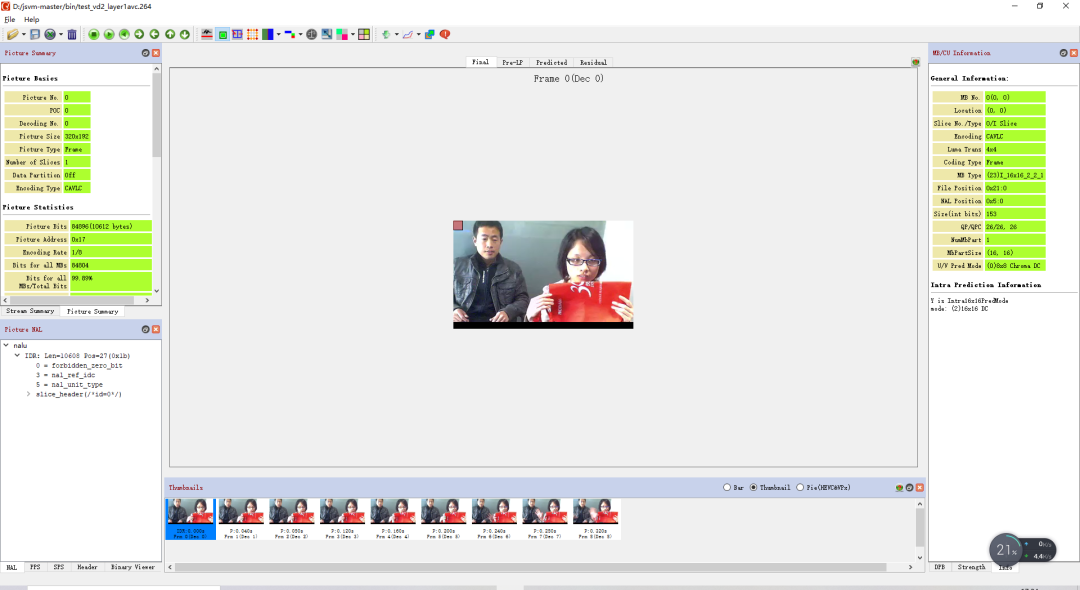
图 20 为用 JSVM 转换之后的码流解码效果,可以用标准的 AVC 解码器解码。
AI 和可分级 编码结合的应用前景和研究方向
可分级编码中最频繁使用的方法是空域可分级技术,但是不同分辨率在转换时,质量下降比较明显。ICME2020 会议上,有学者提出了用于视频编码的超分辨模型,该模型通过提取不同时刻的图像进行特征融合来重建出高分辨率图像。实验结果表明,超分效果有提升。
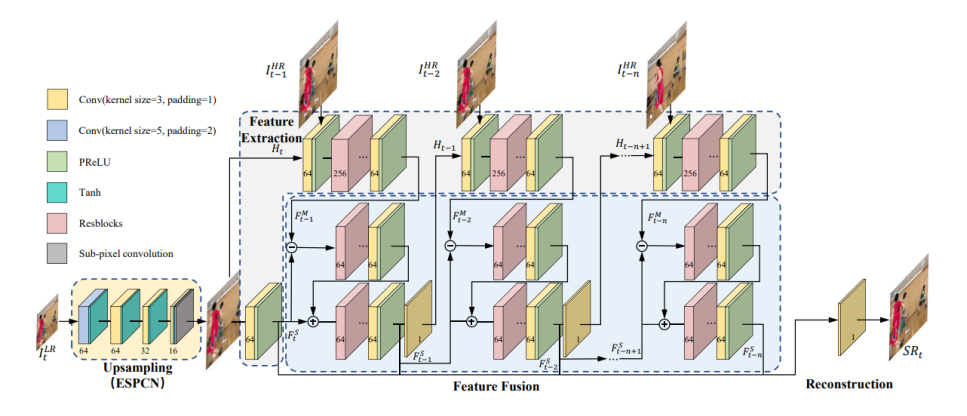
将该模型用于可分级编码器中,可以有效地改善不同分辨率码流切换的时候,给人带来的不适感。
MPEG5 提出了 Low Complexity Enhancement Video Coding(LCEVC),该编码方式和 H.264 相比,在相同的 PSNR 下,压缩效率更高。编码器如图 22 所示。其中基本的编码器 Base Encoder 可以选用任意一种现成的编码器,比如 H.264,VP8,VP9 等。
WebRTC 和 LCEVC 相互结合,是未来的一个发展方向。作为一个新的视频编码标准,其具有几个特征:提升了基本层编码的压缩能力,具有低编码和解码复杂度,提供了一个额外的特征增强平台等。
从图 22 可以看出,编码复杂度主要在取决于 Base Encoder,在 WebRTC 中广泛使用的 H.264 如果采用 LCEVC 的方式进行增强,在复杂度增加的情况下,编码效果会有明显地提升。一般而言采用 H.264 编码的 1080P 高帧率的实时体育视频流需要 8Mbps 的最高码率,而采用 LCEVC 仅仅需要 4.8Mbps。
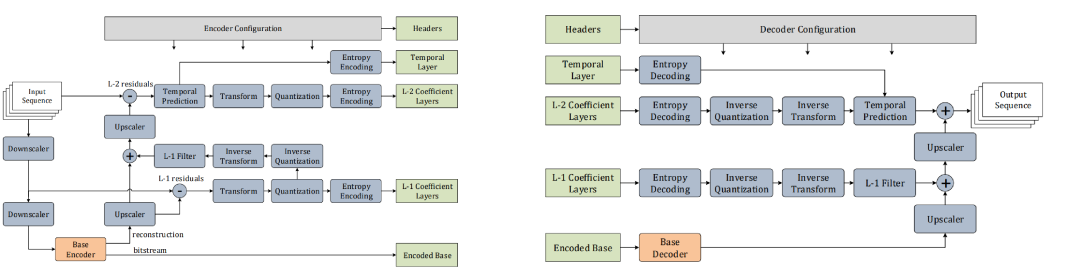
鉴于 LCEVC 编码的效果,可以判断,LCEVC 和 WebRTC 结合,将是一个重要的研究和应用方向。