
Facebook 开源的无损压缩算法:zstd
Zstandard (也被称为zstd )是一款免费的开源,快速实时数据压缩程序,具有更好的压缩比,由Facebook开发。
它是用C语言编写的无损压缩算法 (在Java中有一个重新实现)。因此它是一个本地Linux程序。
当需要时,它可以将压缩速度交换为更高的压缩比率(压缩速度与压缩比率的权衡可以通过小增量来配置),反之亦然。 它具有小数据压缩的特殊模式,称为字典压缩,可以从任何提供的样本集中构建字典。 它带有一个命令行实用程序,用于创建和解码.zst , .gz .xz 和 .lz4 文件。
重要的是,Zstandard拥有丰富的API集合,支持几乎所有流行的编程语言,包括Python,Java,JavaScript,Nodejs,Perl,Ruby,C#,Go,Rust,PHP,Switft等等。
Benchmarks
作为参考,一些快速压缩算法在一个运行 Arch Linux (Linux 版本5.5.11-arch1-1)的服务器上进行了测试和比较,使用了 Core i9-9900K CPU@5.0 GHz,使用 lzbench,一个由@inikep 在西里西亚压缩语料库上用 gcc 9.3.0编译的开源内存基准测试。
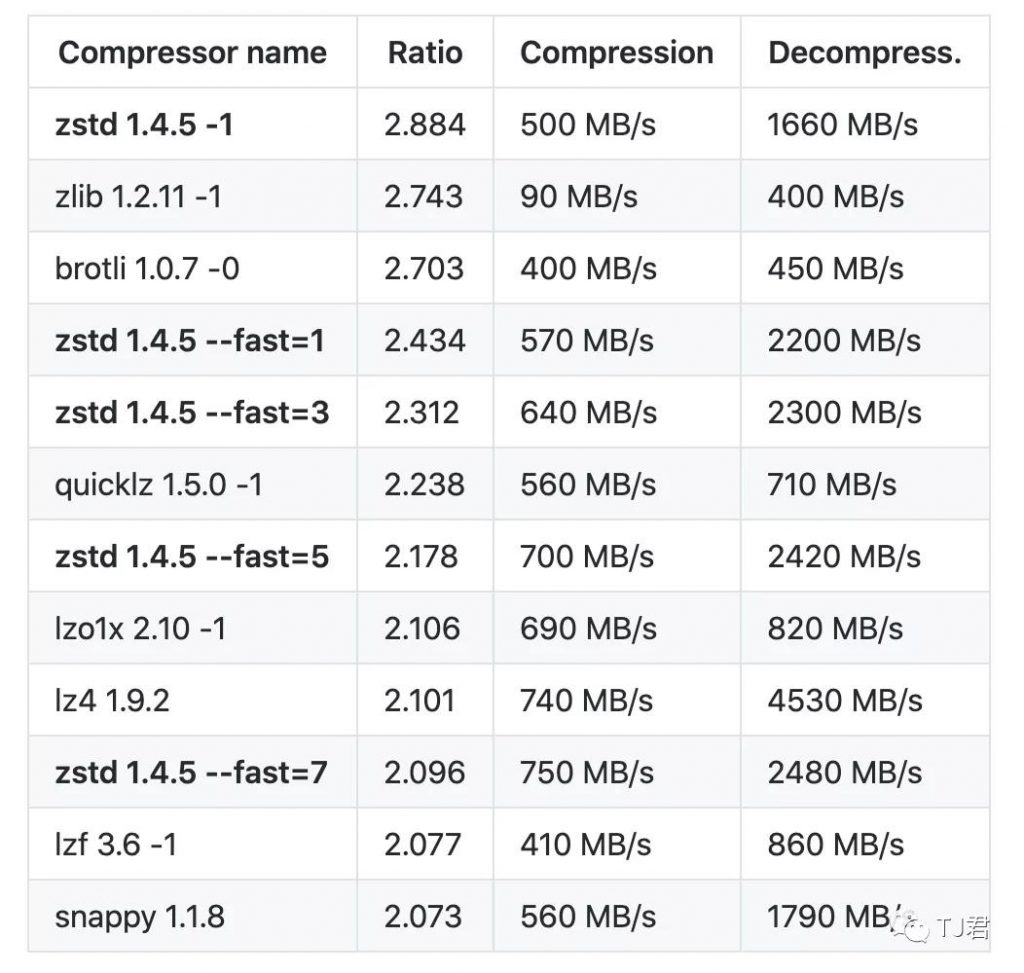
其中–fast代表负压缩级别,提供更快的压缩和解压缩度,以换取相对于1级的压缩比损失。
小型数据压缩的案例
前面的图表提供的结果适用于典型的文件和流场景(几MB的大小)。
要压缩的数据量越小,压缩就越困难。这个问题在所有的压缩算法中都很常见,原因是压缩算法从过去的数据中学习如何压缩未来的数据。
为了解决这个问题,Zstd 提供了一种训练模式,可以用来对选定类型的数据进行算法调优。通过提供一些样本(每个样本一个文件)来实现 Zstandard 的训练。这种训练的结果存储在一个名为“ dictionary”的文件中,必须在压缩和解压缩之前加载该文件。使用这本字典,可以在小数据上实现的压缩比/值大大提高。
下面的示例使用 github-users 示例集,该示例集是从 github public API 创建的。它由大约10K 条记录组成,每条记录重约1KB。
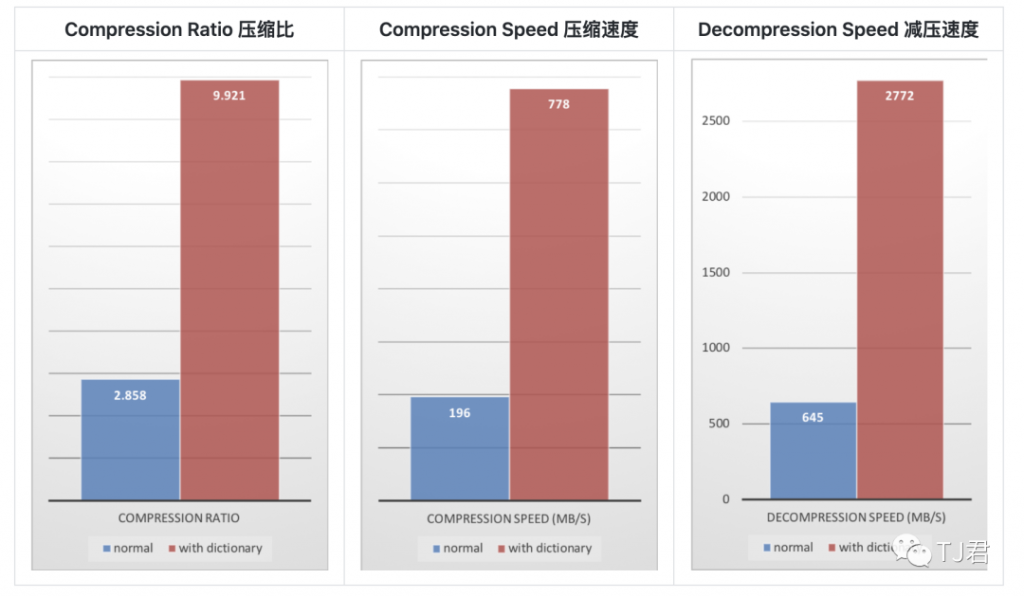
这些压缩增益的实现,同时提供更快的压缩和解压缩速度。
如果在一组小数据样本中存在某种相关性,则训练是有效的。一个字典的数据特定性越强,它的效率就越高(没有通用的字典)。因此,为每种类型的数据部署一个字典将带来最大的好处。字典增益在前几个 KB 中最有效。然后,压缩算法将逐渐使用先前解码的内容,以更好地压缩文件的其余部分。
那么你的应用中有需要用到压缩场景的吗?
不妨试试Facebook的这个开源库,看看能否给你的压缩过程提提速!
来源于公众号-程序猿DD
 预约咨询专属顾问
预约咨询专属顾问