WebRTC 音频抗弱网技术(上)
人均社恐,钟爱语聊。以语聊房为代表的语音社交产品解锁陌生人社交新方式,也不断讲述着新的出圈故事。
而声音卡顿、断断续续、快进、慢放等现象会严重影响用户体验,直接导致用户离开,这些都是弱网引起的常见问题。
本文主要从音频应用的角度来分析常用的弱网对抗技术,主要有如下几种:
- 前向纠错技术(FEC、RED 等)
- 后向纠错技术(ARQ、PLC 等)
- 编码器抗弱网特性(本文重点关注 OPUS 编码器的特性)
- 抗抖动技术(JitterBuffer)
我们将用上、下两篇文章,结合 WebRTC 中使用或支持的音频抗弱网技术,对以上几类技术做分析,以实现音频通信服务在弱网环境下高可用。
上篇主要分享前向纠错技术、后向纠错技术及 OPUS 编解码抗弱网特性;下篇专题分享 WebRTC 使用的抗抖动模块 NetEQ。
前向纠错技术
FEC
前向纠错技术,最典型的就是 FEC 技术了。
发送端:生成冗余包来对抗传输过程中丢包的问题;
接收端:对收到的冗余包和正常包来重新恢复传输过程中丢失的包。
FEC 分带内和带外两种,WebRTC 中视频是通过带外 FEC(ULPFEC[1]、FLEXFEC[2])来产生冗余包,音频则是通过 OPUS 带内 FEC 来生成冗余包。
带内 FEC 由于会占用一部分编码码率,所以对音频的音质会有所降低。带外 FEC 不会影响音质,但会额外占用网络带宽,各有优缺点。
FEC 典型的编码方式有 XOR 和 Reed Solomon[3]。WebRTC 的带外 FEC 使用的是 XOR 编码方式(ULPFEC和FLEXFEC),其特点是计算量相对少,但其抗丢包能力有限。
在 WebRTC 中,带外 FEC,不论是 ULPFEC,还是 FLEXFEC 都是根据 MASK 掩码来确定 FEC 包和被保护的源 RTP 包的映射关系,其中定义了两种类型的掩码,RandMask 和 BurstMask,前者在随机丢包中保护效果要好些;后者则是对突发导致连续丢包效果会好些,但是不论哪种,都有其缺点;这里以 7-4 掩码(即 7 个原始包,将生成 4 个冗余包)举例:
#define kMaskBursty7_4 \
0x38, 0x00, \
0x8a, 0x00, \
0xc4, 0x00, \
0x62, 0x00将上面十六进制按照二进制展开如下:
包序号: S1 S2 S3 S4 S5 S6 S7
R1: 0 0 1 1 1 0 0 原始包S3,S4,S5被冗余包R1保护
R2: 1 0 0 0 1 0 1 ==> 原始包S1,S5,S7被冗余包R2保护
R3: 1 1 0 0 0 1 0 原始包S1,S2,S6被冗余包R3保护
R4: 0 1 1 0 0 0 1 原始包S2,S3,S7被冗余包R4保护上面的掩码表示根据 S1-S7 共 7 个原始包,发送端将生成 4 个冗余包 R1-R4,其中:
R1 包保护 S3,S4,S5 三个原始包
R2 包保护 S1,S5,S7 三个原始包
R3 包保护 S1,S2,S6 三个原始包
R4 包保护 S2,S3,S7 三个原始包从上也可以看出,每个原始包都有被冗余包保护;当包丢失了,一般可以通过冗余包和收到的原始包来进行恢复,比如发送端发送了 S1-S7、R1-R4 共 11 个包,接收端收到了 S1、S3、S5、S7、R1、R2、R3、R4 共 8 个包,丢失了 S2、S4、S6 三个包;则 S2、S4、S6 修复过程如下:
S2 可以被 R4、S3、S7 修复,即 S2 = R4 XOR S3 XOR S7
S4 可以被 R1、S3、S5 修复,即 S4 = R1 XOR S3 XOR S5
S6 可以被 R3、S1、S2 修复,即 S6 = R3 XOR S1 XOR S2但是也有些包无法修复,比如丢失了 S1、S2、S7,则无法恢复,原因如下:
根据掩码保护关系可知,S1 的恢复可以通过 R2、S5、S7 或者 R3、S2、S6;但因为 S7 和 S2 丢失,要恢复 S1,需要先恢复 S2 或 S7
同样,S2 可以通过 R3、S1、S6 恢复,但因为 S1 丢失,则需要先恢复 S1
同理,S6 可以通过 R3、S1、S2 恢复,但是需要先恢复 S1、S2
所以,经过上面的分析可知 S1、S2、S7 均⽆法恢复根据掩码保护关系可知,S1 的恢复可以通过 R2、S5、S7 或者 R3、S2、S6;但因为 S7 和 S2 丢失,要恢复 S1,需要先恢复 S2 或 S7
同理,要是丢失了 S3、S5、S7,也无法恢复,这是 WebRTC 中采用掩码来确定冗余包和原始包之间的保护关系的技术缺点。
即对于(M 个原始包 + N 个冗余包)一组包,有小于等于 N 个包丢失时,可能无法恢复丢失包的情况。
Reed Solomon 编码则可以做到对于(M 个原始包 + N 个冗余包)一组包,有小于等于 N 个包丢失,都可以将丢失的包恢复。
RS FEC 主要是使用范德蒙矩阵或者柯西矩阵来进行编解码[4],柯西矩阵效果比范德蒙矩阵计算量少,性能更优;但不论上面何种矩阵,它们都具有⼀个特性就是可逆,且任意子矩阵可逆,这就保证了在丢失小于等于 N 个包时,RS 能将其恢复。
下面以范德蒙矩阵做简要说明。以(7,4)为例,即 7 个原始包产生 4 个冗余包,原始包为 S1、S2、S3、S4、S5、S6、S7,冗余包为(R1、R2、R3、R4)。原始包和冗余包的关系如下:

其中上面的范德蒙矩阵为 A,如下所示:
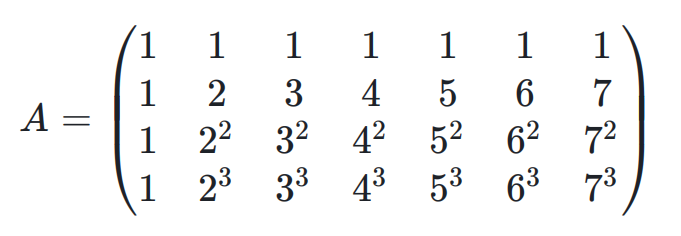
单位矩阵表示如下:

假设 S2 、S4 两数据包丢失了,则将公式 1 中的单位矩阵对应的行删除,则有如下:

公式 2 左侧的矩阵记为 B,如下:

根据范德蒙矩阵可逆特点, 所以 B 也是一个可逆矩阵,记为 B,则恢复包过程其实主要就是求解 B' 矩阵的过程,对公式 2 做如下推导,即可求解原始包,如下所示:
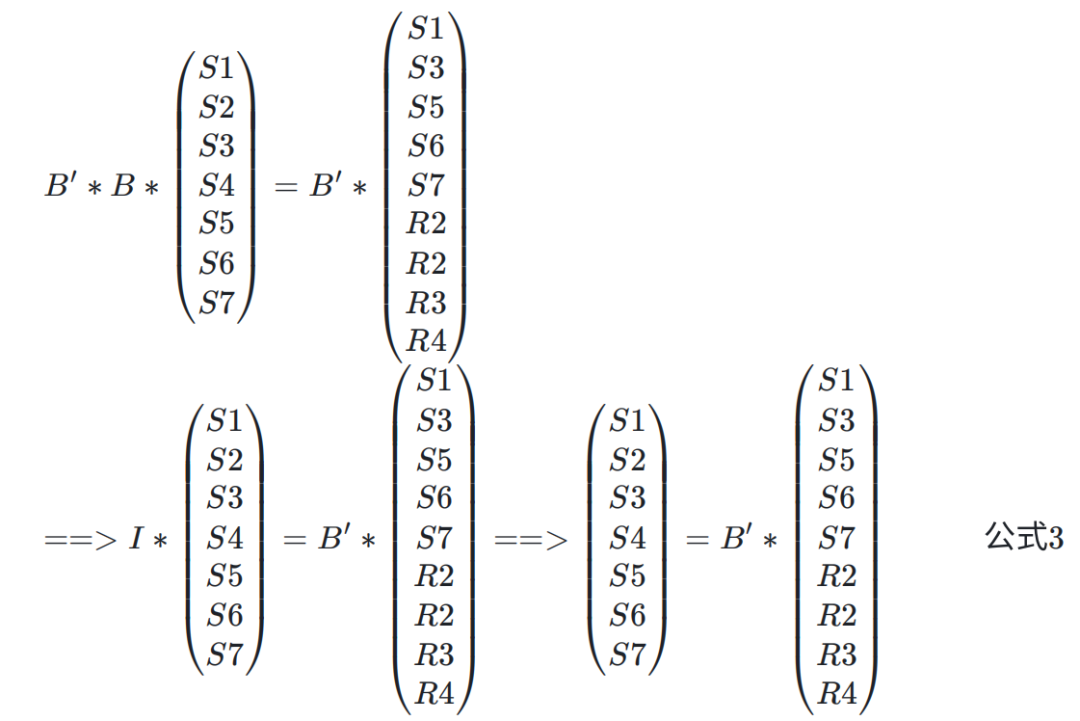
即 (S1、S2、S3、S4、S5、S6、S7)中任何一个包都可以通过矩阵 B' 和收到的包进行恢复。所以 RS 的保护能力更强。
RED
RED 也是前向纠错的⼀种方式,发送端通过主动发送冗余码,来在⼀定程度上抵抗包在传输网络丢失的问题。解码端可以通过冗余包恢复丢失的包,RED 的标准规范在 RFC2198 中定义,可用在视频和音频冗余包生成,WebRTC 音频在 m96 上开启了 RED 方式。
RED 的 payload 中不但包含当前包,还包含了历史包,这样 payload 在⼀定程度上具有冗余信息,起到抗丢包的作用。
下面简要介绍下 RED 的封装格式:RED block head
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|F| block PT | timestamp offset | block length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
F: 1表⽰当前block后还有其它block, 0表⽰当前block为最后⼀个block
block PT: 表⽰当前block 的payload type
timestamp offset: 表⽰当前包时间戳相对于rtp head的时间戳的偏移
block length: 表⽰当前block的⻓度,不包括当前block header⻓度
0 1 2 3 4 5 6 7
+-+-+-+-+-+-+-+-+
|0| Block PT |
+-+-+-+-+-+-+-+-+
表⽰最后⼀个block下面是一个 RED 包的示例:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|V=2|P|X| CC=0 |M| PT | sequence number of primary |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| timestamp of primary encoding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| synchronization source (SSRC) identifier |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|1| block PT=7 | timestamp offset | block length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|0| block PT=5 | |
+-+-+-+-+-+-+-+-+ +
| |
+ LPC encoded redundant data (PT=7) +
| (14 bytes) |
+ +---------------+
| | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ +
| |
+ +
| |
+ +
| |
+ +
| DVI4 encoded primary data (PT=5) |
+ (84 bytes, not to scale) +
/ /
+ +
| |
+ +
| |
+ +---------------+
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
该 rtp 包是⼀个 RED 封装,包含两个 block, ⼀个 block type 为 7, ⼀个 block type 为 5;即该 rtp 包包含了两中类型的数据包。WebRTC 中使用 RED 包来生成 audio 冗余包,其原理大致如下:
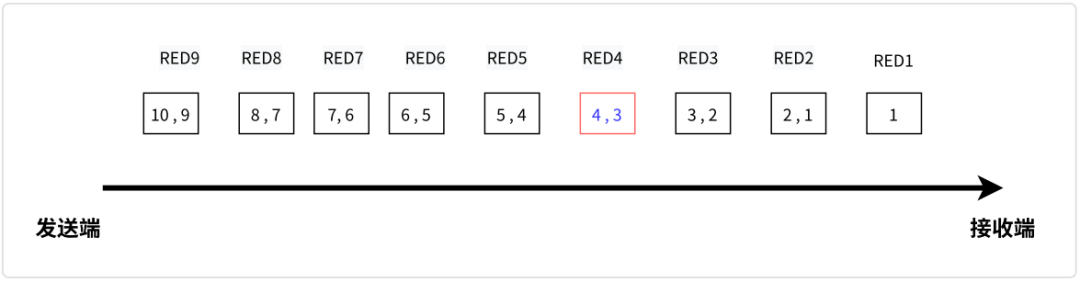
上图中,发送端除了发送当前包,还会携带之前一个包做为冗余包,当上图的 RED4 包丢失,即 4,3 包丢掉时,后续的 RED5 包到达,包含了 5,4 包,结合之前 RED3 包(包含了 3, 2 包),可以恢复丢失的包。
后向纠错技术
ARQ
ARQ 为丢包重传技术,接收端通过向发送端请求重发丢失的包来恢复丢失的包。
这个相对于前向纠错技术来讲,延时偏高,在延时小的情况下,是个比较合适的选择。
原理如下所示:
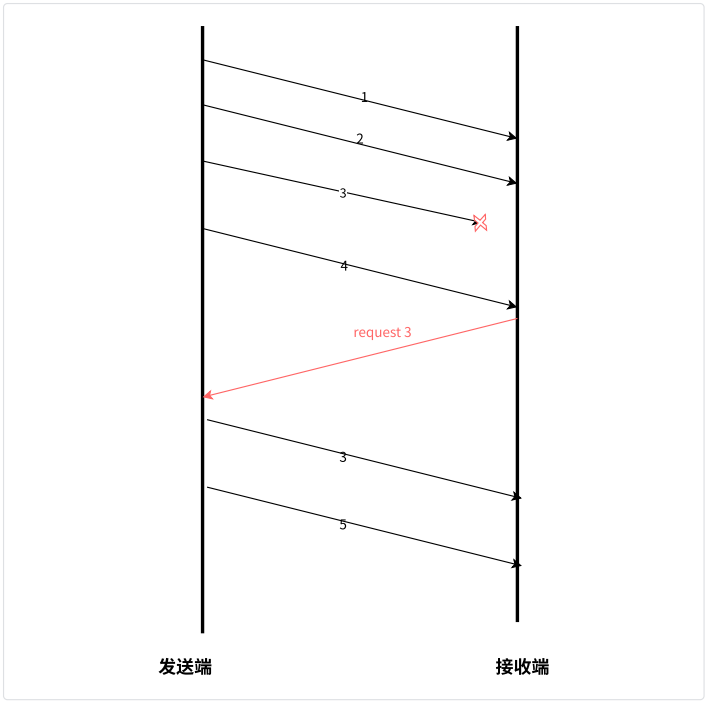
数据包 3 第⼀次发送时,接收端没有收到,便向发送端发起 3 的重传请求(WebRTC 中使⽤ NACK RTCP 包),发送端收到了接收的重传请求后,则再次重发报文 3。
下面是对 WebRTC 中使用的 NACK[6]RTCP 格式的简单介绍,NACK RTCP 在 RFC4585 中有介绍,NACK 属于反馈消息,即 Feedback Message,格式如下:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|V=2|P| FMT | PT | length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| SSRC of packet sender |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| SSRC of media source |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
: Feedback Control Information (FCI) :
: :
Figure 3: Common Packet Format for Feedback MessagesPT 有两种大类型:
Name | Value | Brief Description
----------+-------+------------------------------------
RTPFB | 205 | Transport layer FB message
PSFB | 206 | Payload-specific FB messageNACK 对应的 FCI 消息格式如下:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| PID | BLP |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Figure 4: Syntax for the Generic NACK message
NACK的PT=RTPFB 且 FMT=1
PID表⽰当前重传请求的第⼀个seqnum
BLP为16位,代表PID所指的seqnum后连续的16个seqnum的重传请求情况, 1表⽰当前位对应的se qnum丢失,接收端对其进⾏了重传请求, 0表⽰未对该位对应的seqnum做重传请求
NACK中可以携带多个FCI端PLC
PLC 称之为丢包隐藏技术,位于接收端,也即解码端;解码端根据历史语音帧,对其进行信号分析,通过线性预测系数进行 LPC 建模,来预测丢失的语音帧,这项技术的可行性是基于语音的短时语音相似性。
其优点是,不占用额外带宽;PLC 技术可以处理较小的丢包率(<15%)。
NetEQ 中的丢包隐藏是根据上一语音帧的线性预测系数 PLC 来建模,根据历史语音信号重建语音信号然后加载一定的随机噪声;
连续丢包隐藏时,均使用同一个线性预测系数 LPC 重建语音信号,注意这⾥需要减少连续重建信号间的相关性,因此丢包隐藏产生的数据包能量递减;
最后为了语音连续,需要做平滑处理。当需要进行丢包补偿时,从存储最近 70ms 的语音缓冲区中取出最新的一帧数据并计算该帧的 LPC 系数即可WebRTC 的 NetEQ 模块和 OPUS 解码器都具有 PLC 的功能,要是 Decoder 支持 PLC,优先使用解码器的 PLC 功能,否则使用 NetEQ 的 PLC 功能,下一篇文章在介绍 NetEQ 模块时,会进行较详细说明。
编码器 OPUS 抗弱网特性
OPUS 不但是开源且无专利的编解码器, 而且相比其它编解码器来说,性能十分优越。这也是 WebRTC 音频通常使用它的原因。
下面对 OPUS 的一些特性进行说明,这些特性在对抗弱网上都有非常大的帮助。
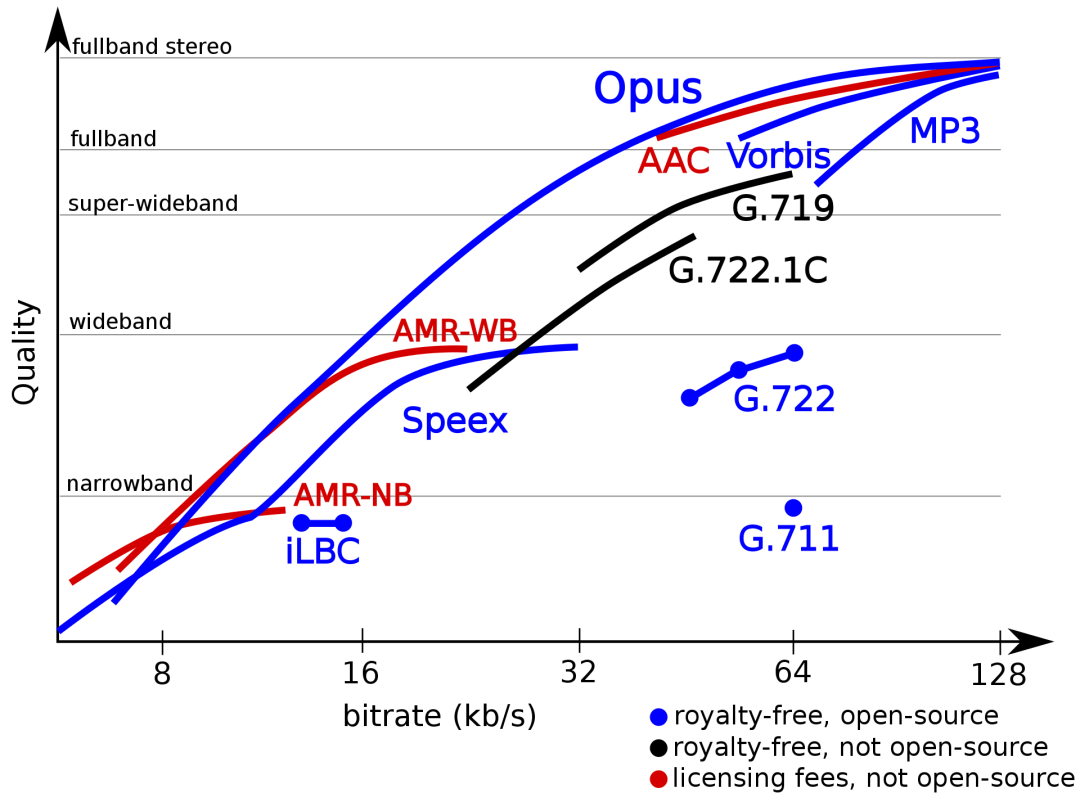
⽀持全频带带宽
OPUS 支持的码率可以从窄带 6kbps 到⾼品质立体声 510kbps,下面这幅图说明 OPUS 从窄带到高品质宽带都能覆盖,且相同码率下,品质更高。
OPUS 支持动态码率调准
可以无缝调节码高低,同等码率下,OPUS 的音效品质更高;同时在丢包情况下,当丢包率大于一定范围时,会将编码模式转换成为 SILK 模式,即低码率模式,以适应网络情况。
//设置码率接⼝,可以通过该接⼝动态调整码率
WebRTCOPUS_SetBitRate
/* When FEC is enabled and there's enough packet loss, use SILK */
if (st->silk_mode.useInBandFEC && st->silk_mode.packetLossPercentage > (128-vo ice_est)>>4)
st->mode = MODE_SILK_ONLY;OPUS延时更低
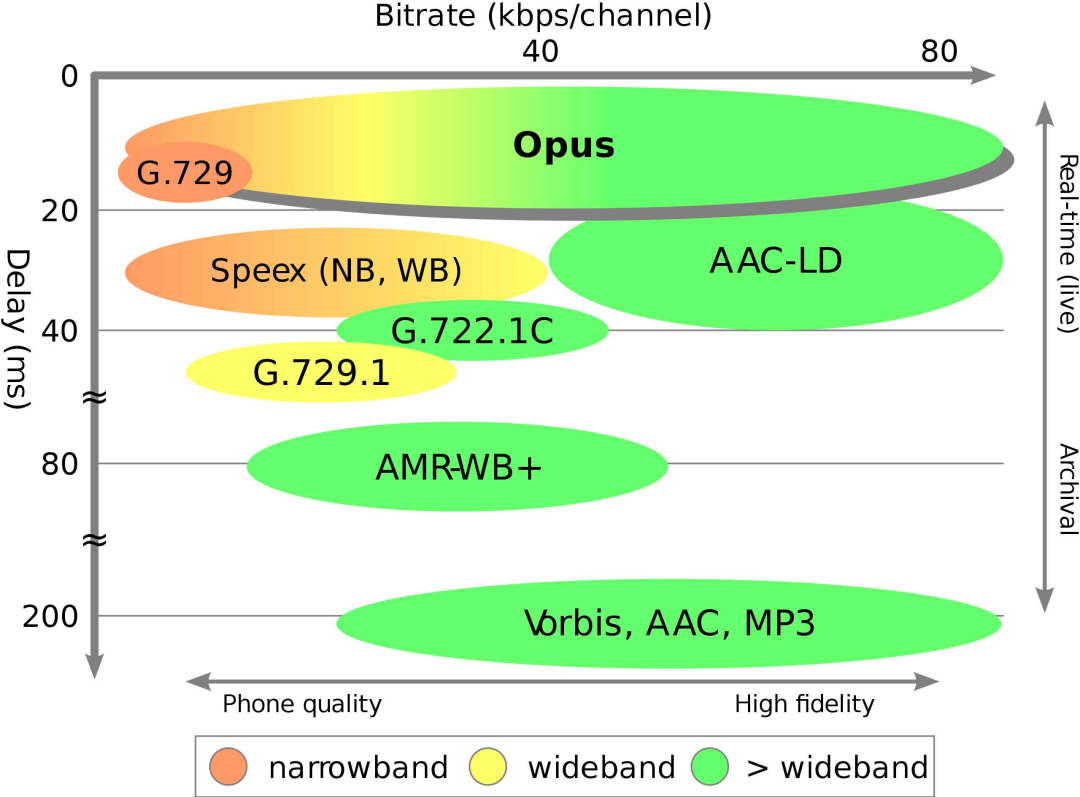
OPUS 结合了两种编解码技术,SILK(用于语音)和CELT(用于音乐),具有低延迟优势。
这对于用作低延迟音频通信链路的一部分是必不可少的, OPUS 可以以牺牲语音质量为代价将算法延迟减少到 5 毫秒。
现有的音乐编解码器(例如 MP3、Vorbis 和 HE-AAC)具有 100 毫秒或更多的延迟,而 OPUS 的延迟要低得多,但在质量上与比特率相当,如下图所示:
OPUS支持带内 FEC
OPUS 支持带内 FEC 功能,在使用 FEC 后,可以根据丢包率来生成冗余包,提高音频的抗丢包能力。
OPUS 的带内 FEC 功能使用方式类似 RED 方法,即发送当前包时,会携带上一个包的内容,只不过是上一个包是使用低码率编码来产生冗余包的,类似下面的方式:
1| | -> |2|1| -> |3|2| -> |4|3| -> |5|4| -> |6|5|下面是 OPUS 和 FEC 相关的几个接口:
//使能内置FEC
WebRTCOPUS_EnableFec
//向OPUS传递丢包率
WebRTCOPUS_SetPacketLossRate
//根据丢包率及useInBandFEC来判断是否开启低码率编码,即利⽤低码率编码来上⼀帧语⾳帧,⽣成 冗余包
st->silk_mode.LBRR_coded = decide_fec(st->silk_mode.useInBandFEC,
st- >silk_mode.packetLossPercentage, st->silk_mode.LBRR_coded, st->mode, &st->bandwidth, equiv_rate);
//根据是否⽀持FEC,来分配SILK rate
static int compute_silk_rate_for_hybrid(int rate, int bandwidth, int frame20ms, int vbr, int fec)
/* Low-Bitrate Redundancy (LBRR) encoding.
Reuse all parameters but encode excitation at lower bitrate */
static OPUS_INLINE void silk_LBRR_encode_FLP(
silk_encoder_state_FLP *psEnc, /* I/O Encoder state FLP */
silk_encoder_control_FLP *psEncCtrl, /* I/O Encoder control FLP */
const silk_float xfw[], /* I Input signal */
OPUS_int condCoding /* I The type of conditional coding used so far for this frame */
)这里需要指出的是,OPUS 内置的 FEC 包只在 SILK 模式下生成,CELT 编码模式下是不生成冗余包的。
if (st->mode == MODE_CELT_ONLY)
redundancy = 0;
if (redundancy)
{
redundancy_bytes = compute_redundancy_bytes(max_data_bytes, st- >bitrate_bps, frame_rate, st->stream_channels);
if (redundancy_bytes == 0)
redundancy = 0;
}WebRTC 中 FEC 的功能开启是通过 SDP 协商来完成的,如下所示:
a=rtpmap:111 OPUS/48000/2
a=fmtp:111 minptime=10;useinbandfec=1下图是 OPUS 开启 FEC 和没开启 FEC 的效果对比图
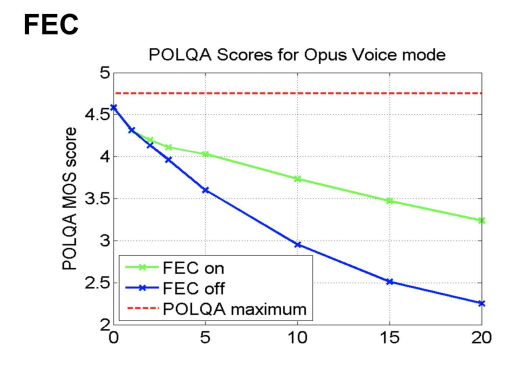
从图中可以看出,FEC 开启后,在 20% 丢包情况下,音频 MOS 值提升还是非常明显的。
OPUS 解码端支持 PLC
OPUS 解码端支持丢包隐藏,其原理是根据语音信号具有短时相似性的特点,利用上一帧正常或恢复的语音信号,对其进行信号分析,重建和预测当前丢失的语音帧。
int WebRTCOPUS_Decode(OPUSDecInst* inst, const uint8_t* encoded,
size_t encoded_bytes, int16_t* decoded,
int16_t* audio_type) {
int decoded_samples;
if (encoded_bytes == 0) {
*audio_type = DetermineAudioType(inst, encoded_bytes);
decoded_samples = WebRTCOPUS_DecodePlc(inst, decoded, 1);
} else {
...
}OPUS 语音功能支持 DTX
当不是音乐模式时,即在 VoIP 模式下,当检测到某个时间期间内没有说话声时,为了节省带宽,可以将开启 DTX。
这个时候,在没有检测到通话声音时,OPUS 会定期 400ms 发送静音包,达到降低带宽的目的,WebRTC 默认没有开启这个特性,要开启 DTX,只需要 SDP 协商时,在 a=ftmp 这一行中加入 usedtx=1 即可开启。
WebRTCOPUS_EnableDtx
WebRTCOPUS_OPUS 本⾝具有很多抗弱网的特性,这些特性再配合丢包重传,可以使音频具备很强的抗弱网能力。
本文主要结合实际弱网处理工作经验,从前向纠错、后向纠错及 OPUS 编码器本身特性等方面,对音频弱网一些常用技术做简要说明和总结。
弱网处理还有一个关键的抗抖动技术,将在该系列的下一篇文章中详细介绍。


