当 WebRTC 遇上 AI,融云的音视频产品优化实践
WebRTC(网页实时通信),作为一个支持网页浏览器进行实时语音或视频对话的开源技术,解决了互联网音视频通信的技术门槛问题,正逐渐成为全球标准。
过去十年间,在众多开发者的贡献之下,这项技术的应用场景越来越广泛和丰富。在人工智能时代,WebRTC 将走向何方?本文主要分享 WebRTC 与人工智能技术结合的相关方向及融云的创新实践。
WebRTC+人工智能,让声音更真切、视频更高清
人工智能技术在音频和视频方面的应用越来越来广泛,在音频方面,人工智能技术主要用于噪声抑制(noise suppression)、回声消除(echo removal)等;在视频方面,人工智能技术则更多用于虚拟背景、视频超分辨率等。
AI语音降噪
语音降噪已经有多年历史,最早常使用模拟电路降噪方法。随着数字电路的发展,降噪算法代替传统模拟电路,大大提升了语音降噪的质量。这些经典的算法都基于统计理论估计噪声,能够将稳态噪声消除得比较干净。对于非稳态噪声,如敲击键盘、桌子的声音,马路上车来车往的声音,经典算法就显得无能为力了。
AI 语音降噪应运而生,它基于大量语料,通过设计复杂的算法,结合持续的训练学习而成,省去了繁琐而模棱两可的调参过程。AI 语音降噪在处理非稳态噪声时有着天然优势,它能识别非稳态数据的特征,有针对性地降低非稳态噪音。
回声消除
回声是由于扬声器放出来的声音经过衰减和延时后又被麦克风收录产生的。我们在发送音频时,要把不需要的回音从语音流中间去掉。WebRTC 的线性滤波器采用频域分块的自适应处理,但并没有仔细考虑多人通话的问题,非线性回声消除部分采用维纳滤波的方法。
结合人工智能技术,我们可以基于深度学习方法,采用语音分离方式,通过精心设计的神经网络算法,直接消除线性回声和非线性回声。
虚拟背景
虚拟背景依托于分割技术,通过将图片中的前景分割出来,对背景图片进行替换得以实现。主要应用场景包括直播、实时通讯、互动娱乐,涉及到的技术主要包括图像分割和视频分割。典型的实例如图 1 所示。

视频超分辨率
视频超分辨率是将高糊视频变清晰,在带宽受限、码率较低的情况下,传输较低质量的视频,然后通过图像超分辨率技术还原成高清视频,这一技术在 WebRTC 中具有重要意义。典型的图像如图 2 所示。在带宽有限的情况下,传输低分辨率的视频码流,依然可以获得高分辨率的视频。

融云的创新实践
WebRTC 是一个开源技术栈,想真正在实际场景下做到极致,还需要进行大量的优化。融云结合自身的业务特点,对 WebRTC 音频处理和视频压缩部分源代码进行修改,用以实现基于深度学习的音频噪声抑制和视频高效压缩。
音频处理
除了 WebRTC 原有的 AEC3、ANS 和 AGC 外,针对会议、教学等纯语音场景,融云加入了 AI 语音降噪模块,并对 AEC3 算法做了优化,大大提高音乐场景下的音质。
AI语音降噪:业界大都采用时域和频域的 mask 方法,结合了传统算法和深度神经网络。通过深度神经网络估计信噪比,可以计算出不同频段的增益,转换到时域后,再次计算一个时域的增益,最后应用到时域上,可以最大限度消除噪声,保留语音。
由于深度学习语音降噪模型过多采用 RNN (循环神经网络),所以语音结束一段时间内,模型依然认为有人声存在,拖延时间太长以至于语音无法掩蔽掉残余噪声,导致语音结束后短暂的噪声。融云在现有模型的基础上添加预测模块,根据语音幅度包络和 SNR 下降程度,提前预测到语音的结束,消除在语音结束时能够察觉到的残余噪声。
视频处理
在 WebRTC 源码中,视频编码部分主要采用了开源的 OpenH264、VP8、VP9 并重新封装成了统一的接口。融云通过修改 OpenH264 源码完成背景建模和感兴趣区域编码等任务。
背景建模:为了完成实时的视频编码,将背景建模的处理放在 GPU 上十分必要。经过调研发现,OpenCV 中的背景建模算法支持 GPU 加速。实际操作中,我们将摄像头等采集设备获取的原始 YUV 图像转成 RGB 图像,再将 RGB 图像送入 GPU 中。然后,在 GPU 中获取背景帧并将其从 GPU 转移到 CPU 中。最后,再将该背景帧加入到 OpenH264 的长期参考帧列表中,用于提高压缩效率。流程图如图 5 所示。

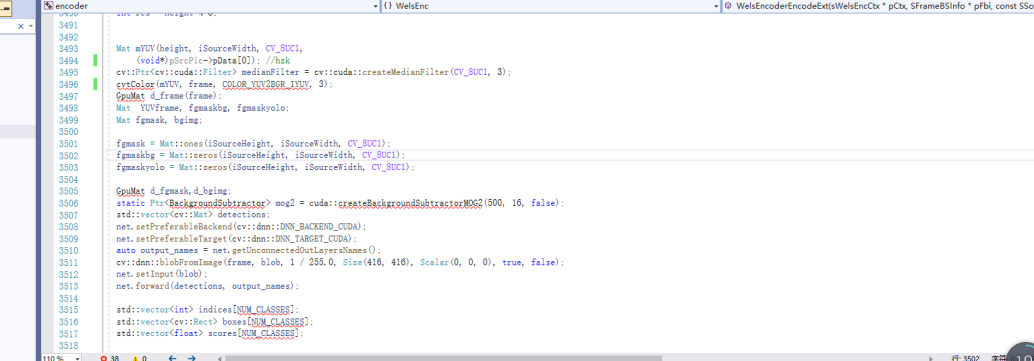
感兴趣区域提取:感兴趣区域编码部分实现采用了 yolov4tiny 模型,进行目标检测以及与背景建模提取的前景区域融合。部分代码展示下图 6 所示。网络加载后,选择 cuda 进行加速,输入图像设置为 416*416。
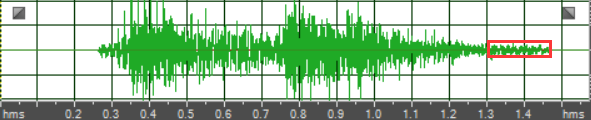
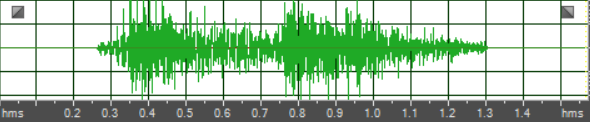
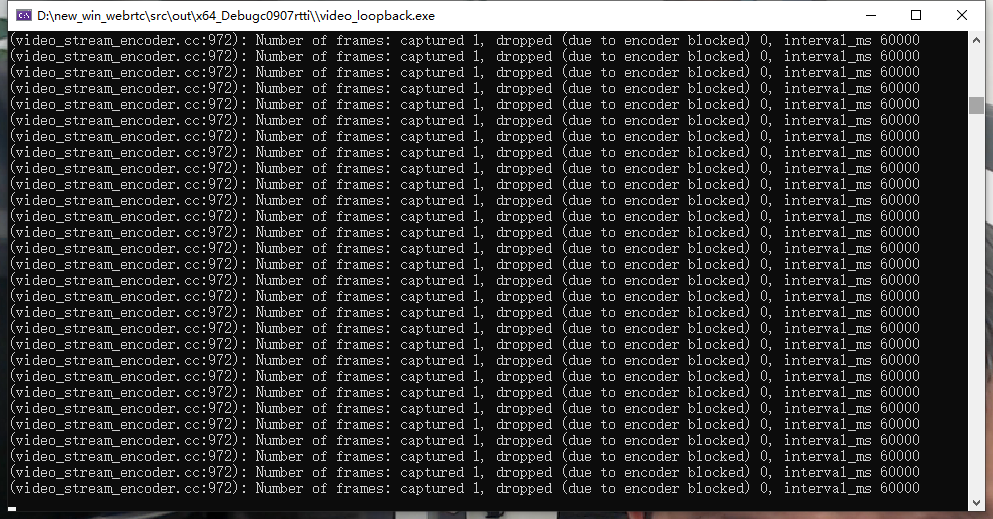
视频编码在 WebRTC 上的实验效果:为了验证效果,我们采用 WebRTC 中的 videoloop 测试程序对修改的 OpenH264 进行测试。图 7 为摄像头现场采集的视频,选用 1920*1080 分辨率进行背景建模的效果。图 8 为输出的结果,WebRTC 为了保证实时性,会抛弃由于各种原因未在设定的时间内实际编码的帧。图 8 显示,我们采用的算法没有消耗很大的编码时间,没有使编码器产生被抛弃的帧。

总结而言,在音频方面采用基于人工智能的降噪处理,可以显著提高现有语音通话的体验,但是模型预测还不够精准,计算量相对较大。随着模型的不断完善优化,数据集的不断扩大,AI 语音降噪技术一定会为我们带来更好的通话体验。在视频方面,采用背景建模技术将背景帧加入到长期参考帧列表中,有效地提高了监控类场景的编码效率,采用基于目标检测和背景建模以及高效的码率分配方案提高视频感兴趣区域的编码质量,有效地改善了在弱网环境下人们的观看体验。
技术更迭步履不停,我们已经迈入了全面智能化时代。人工智能技术深度应用于各类场景,在音视频产业领域,先进技术与 WebRTC 相结合,亦是前景广阔。服务优化永无止尽,融云将继续紧跟科技趋势,不断对创新科技进行积极探索,并将其沉淀成为可供开发者便捷使用的底层能力,长期赋能开发者。