抽丝剥茧,谈融云 iOS 混音处理
在无数个深夜“网抑云”时间,除了思考人生,你有没有想过这样一个问题:
声音是如何产生的?这些声音又是如何变成了我们所听的音乐?

概述
回想一下物理上的定义 —— 声音是由物体振动而产生的。
声音是一种压力波,当演奏乐器、拍打一扇门或敲击桌面时,它们的振动都会引起空气有节奏地振动,使周围空气产生疏密变化,形成疏密相间的纵波(可以理解为石头落入水中激起的波纹),由此就产生了声波。
对于两种以上的声音混合在一起的情况,就像交响乐中不同乐器的振动发出不同的声音,多种乐器声音的振动融合后的声音,我们称这种现象为:混音。
在讨论混音前,需要先简单了解一下物理世界中“声音”和计算机中“数字音频”的概念。
数字音频
在自然中人耳的听力频率范围大约是 20Hz ~ 20kHz,其中,人耳对 3kHz ~ 4kHz 频率范围内的声音比较敏感,而对于较低或较高频率的声音,敏感度就会有所减弱。
为了将声音中信息完整保存下来,需要将音频设备的采样率设置在 40kHz 以上。比如平常听的数字音乐,其采样率一般为 44.1kHz 或 48kHz,这样就保证了较高的音质。
音频设备采集到的数据,经过量化编码,最终输出数字信号,即 PCM(Pulse Code Modulation,脉冲编码调制)数据。麦克风的主要工作是将物理声音(也称为模拟信号)转化为数字信号,这个转换过程也被称为模数转换 A/D。
在计算机对声音的数字化处理中,包含三个方面:采样、量化和编码。
采样
为了将模拟信号数字化,首先要对模拟信号进行采样,所谓采样,就是在时间轴上对信号进行数字化。
根据奈奎斯特定理(也称为采样定理),按比声音最高频率高 2 倍以上的频率对声音进行采样,对于高质量的音频信号,人耳能够听到的频率范围是 20Hz ~ 20kHz,所以采样频率一般为 44.1kHz,即:每秒振动 44100 个振动周期的声音,这样就可以保证采样声音达到 20kHz 也能被数字化,从而使得经过数字化处理之后,人耳听到的声音质量不会被降低。
量化
量化是指在幅度轴上对信号进行数字化。
比如用 16 比特的二进制信号来表示声音的一个采样,而 16 比特(一个short)所表示的范围是 [-32768,32767],共有 65536 个可能取值,因此最终模拟的音频信号在幅度上也分为了 65536 层。
在量化编码时,采样大小决定了每个样本的最大可表示范围,比如采样大小 16 位,则其表示的最大数值是 65535。
编码
既然每一个量化都是一个采样,那么如此多的采样该如何进行存储呢? 这就涉及将要讲解的第三个概念:编码。
编码,就是按照一定的格式记录采样和量化后的数字数据,比如顺序存储或压缩存储等。通常所说的音频的裸数据格式就是脉冲编码调制(PCM)数据,描述一段 PCM 数据一般需要以下几个概念:量化格式(sampleFormat)、采样率(sampleRate)、声道数(channel)。
PCM 每分钟需要的存储空间约为 10.1MB,如果仅仅是将其存放在存储设备(光盘、硬盘)中是可以接受的,但是在网络中实时传输的话,那么这个数据量是无法接受的,就必须对音频数字信号进行编码。
音频编码的原理实际上是压缩掉冗余信号。冗余信号是指不能被人耳感知到的信号,包含人耳听觉范围之外的音频信号以及被掩蔽掉的音频信号等。
iOS 音频框架
苹果公司为 iOS 提供了非常丰富的多媒体编程接口,以提高原生应用在多媒体方面的用户体验。图 1 是 iOS 的多媒体框架图。

从图 1 可以看出,在 iOS 中所有的音频技术都构建于 Audio Unit 之上,更上层的是 Media Player、AV Foundation、OpenAL 和 Audio Toolbox,它们封装了 Audio Unit 为特定任务提供增强生产效率的专门 API。
Audio ToolBox
Audio Toolbox 是专门处理声音的一个框架,AudioToolbo 这个库是 C 的接口,偏向于底层,用于在线流媒体音乐的播放,可以调用该库的相关接口处理录制,播放音频,转换格式,解析音频流以及配置音频会话。融云 iOS 音频处理直接使用的是 Audio ToolBox 框架中的 Audio Unit、AU Graph。
① Audio Unit
Audio Unit 根据用途不同,被分成了四大类,分别是:Effect(效果器), Mixer(混音), I/O, Format convert(格式转化)。Effect 和 Format convert 超出了本文的主题,这里不做讨论。
I/O:上面的代码中,使用的 Remote I/O unit(kAudioUnitSubType_RemoteIO)是最常用的,它连接着音频硬件设备,提供了对流入和流出的音频样本数据的低延时访问,也提供了音频硬件设备和应用之前音频格式的转化。
Voice-Processing I/O unit 扩展了 Remote I/O,为 VoIP 和语音聊天应用提供了回声抑制功能,也提供了自动增益校正、语音处理质量调整、静音等功能。
Generic Output unit 也是一种 I/O unit,不在本文讨论的范畴。
Mixer:这里只讨论 Multichannel Mixer unit。它提供了混合多个单声道或者立体声音频流,可以关闭或者开启任何一个输入总线,设置输入增益等。
了解了 Audio Unit 分类,下面讨论下 Audio Unit 的结构。
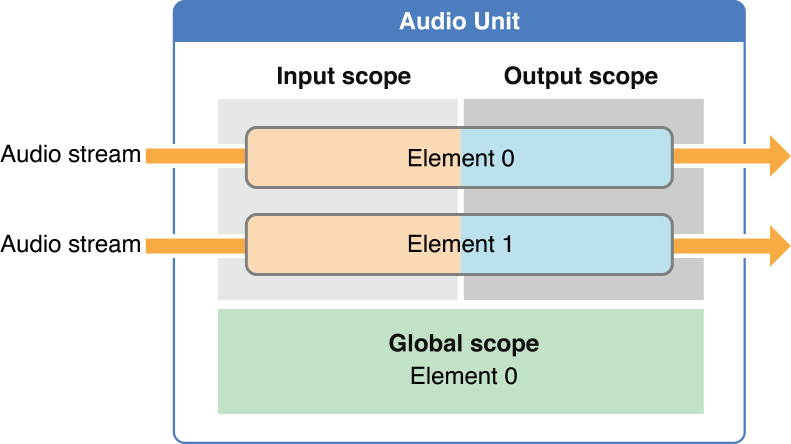
图 2 展示了一个 Audio Unit 的通用结构,它由 Scope(域)和 Element(元素)组成。
这里的 Element 也被称为音频总线(bus),其中 1 表示 Input,0 表示 Output,1 和 0 分别跟 Input 和 Output 的首字母十分相似。
域分为 Input、Output 和 Global,Input 和 Ouput 分别代表一个总线的输入、输出部分,Global 只有一个总线,那就是 0 总线,有些属性只被应用于 Global 域。上面代码片段的属性配置部分使用了这些概念。
另外,上面的 Input Element 和 Output Element 的数量是相等的,然而不同的 Audio Unit 使用了不同结构,例如一个 Mixer Unit 可能有若干个 Input Element,但是只有一个 Output Element。尽管有不同结构的 Audio Unit,但仍然可以将 Scope Element 延伸到任意的 Audio Unit。
② AU Graph
iOS 还提供了 AU Graph 创建和 Audio Unit 处理链管理。AU Graph 具有管理多个 Audio Unit 的能力,使用 AU Node 来表示 AU Graph 中的独立 Audio Unit,在 AU Graph 中通常与 AU Node 交互,而不是与 Audio Unit 交互,AU Node 可以视为 Audio Unit 的代理。
从数据结构的角度来理解,AU Graph 代表一张有向图,其中每一个 Audio Unit 表示图中的一个结点,Audio Unit 总线之间彼此建立的连接,可以认为是结点之间的边,并且这个连接是有方向的,这样节点和边就构成了一个有向图。
构建 AU Graph 需要三个步骤:
·向图中添加节点;
·配置由节点表示的 Audio Unit;
·连接图中各个节点。
混音图
依据上面功能点的描述,将音频数据、音效和音频文件的 Audio Unit 节点连接到同一个混音节点后,即可得到混音后的音频数据。混音逻辑图如下:
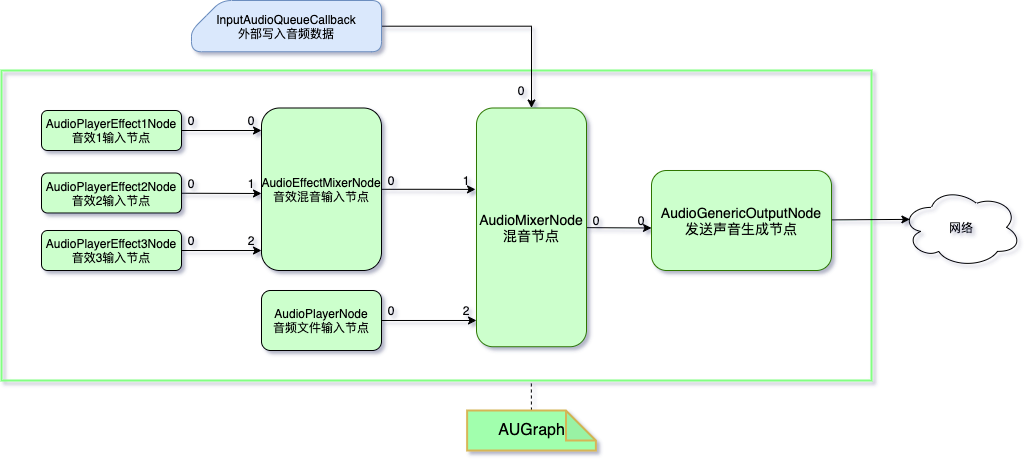
如图 3 所示,图中所有节点均出自同一个 AU Graph。
在音效上可以添加多个音效节点用于同时混音,声音文件也可以存在多个连接到 AudioMixerNode 上,在所有混音节点连接完成后,输出到 AudioGenericOutputNode 节点,最终用于发送或保存。
可见,AU Graph 让开发者有了更大的灵活性去根据自身需求进行设计和使用,以达到多种多样的目的。
结语
本文主要介绍了声音的物理性质、数字音频数模转换的理论知识、iOS 的声音采集方式、Audio Unit 和 AU Graph 的编程概念等内容。
Audio Unit 提供了快速、模块化的音频处理机制,具备低延时的音频 I/O、回声消除、混音、均衡等功能。AU Graph 的处理链体系结构,可将音频模块组装成灵活网络。结合它们可以封装出简洁易用的 AVAudioEngine。在 iOS 应用开发中使用这些技术处理音频任务有很多优势,比如可以轻松让程序获得最佳性能、大幅降低开发成本等。
当然除了 Audio Unit 之外,还可以通过混音算法来实现混音,几乎所有的混音算法都是通过对输入的音频数据做线性叠加衍生出的,比如平均值法、自适应加权等。感兴趣的读者可以比较下这些算法实现的效果和 Audio Unit 的差异。