【融云技术】Native C/C++ 服务适配多指令集 CPU 漫谈
背景介绍
由于近些年,CPU 行业的摩尔定律失效了,很多厂商都纷纷从指令集架构层面寻找替代解决方案。在消费产品领域,苹果推出了 ARM 指令集的 Apple Silicon M1,大获好评;在云服务行业,华为云和 Amazon 前些年就已经在自研并上线了 ARM CPU 服务器,在成本和性能方面颇有建树。
而对于国产 CPU 行业而言,除了北大众志、海光、兆芯等少数几家手上拥有 x86_64 指令集授权外,其他厂家基本都专注于非 x86_64 指令集。如:华为和飞腾在研发 ARM CPU,龙芯常年专注于 MIPS CPU;近些年兴起的 RISC-V 也吸引了众多厂家的目光。对于各种非 x86_64 CPU,行业软件的移植和适配主要会涉及嵌入式端、手机端、桌面端和服务器。嵌入式端考虑到功耗,一般逻辑较为简单,代码移植和适配复杂程度不高。手机端一般都是 Android ARM,不涉及太多适配问题。
桌面端分为三种情况:
- 如果应用基于浏览器即可满足所有功能,国产化系统发型版本,一般内置了 Firefox 浏览器,应用对 Firefox 浏览器进行适配即可。
- 如果应用是一个轻度的桌面应用,可以考虑使用 Electron 的方案。Electron(原名为 Atom Shell)是 GitHub 开发的一个开源框架。它通过使用 Node.js(作为后端)和 Chromium 的渲染引擎(作为前端)完成跨平台的桌面 GUI 应用程序的开发。这种情况下,首先可以看下国产化系统的软件源是否有对应的 Electron 依赖(一般都有);如果没有,需要进行编译。
- 如果应用是一个重度的 Native 应用,则需要把代码在对应的指令集和系统依赖上进行编译,工作量较大。
服务器,也分为三种情况:
- 如果使用的是面向虚拟机的语言,比如 Java 或基于 JVM 的各种语言(Kotlin、Scala 等),则服务不需要进行特殊的适配。一般国产化系统的软件源中一般都会自带已实现好的 OpenJDK;如果没有,参见的指令集一般也都能找到对应的 OpenJDK 开源实现,可以自行安装。
- 近些年出现的一些对 C 库无强依赖的语言,如 Go 等。编译体系在设计之初就考虑了多种目标系统和指令集架构,只需要在编译时指定目标系统和架构即可,如 GOOS=linux GOARCH=arm64 go build,如果使用了 CGO 还需要指定 C/C++ 的编译器。
- 如果服务使用的是 C/C++ 等 Native 语言,且对系统 C 库有强依赖,则需要把代码在对应的指令集和系统依赖上进行编译,工作量较大。
而上面可以看出,服务器和桌面端在 Native C/C++ 的适配上类似,而服务器对性能的要求会更为严苛。本文分享的内容主要是服务器 Native C/C++ 如何在多种指令集 CPU 上进行适配,特别是庞大代码量时如何提高工程效率,大部分内容桌面端也同样可以参考。
编译运行漫谈
既然我们要处理的是 Native C/C++ 程序在多种指令集 CPU 的适配,我们需要先了解下程序是如何编译和运行的,才能在各个环节借助各种工具,提高适配的效率。
大家在上计算机课时一般都有了解,C/C++ 源代码经过预处理、编译和链接,会生成目标文件。然后计算机将程序从磁盘加载到内存中,即可运行。而这中间其实隐藏了非常多的细节,让我们一一来看。
首先,源码在编译过程中,先经过编译器前端,进行词法分析、语法分析、类型检查、中间代码生成,生成与目标平台无关的中间表示代码。然后再交给编译器后端,进行代码优化、目标代码生成、目标代码优化,生成对应指令集的目标 .o 文件。
GCC 在这个过程中是前后端都一起处理了,而 Clang/LLVM 则分别对应了前端和后端。由此我们也能看出,常见的交叉编译是如何实现的,即编译器后端对接到不同的指令集和体系架构上。理论上,所有的 C/C++ 程序都应该能通过本地和交叉编译工具链编译到所有的目标平台。但是实际工程的时候,还需要考虑到实际使用的编译工具,如 make、cmake、bazel、ninja 是否已经能支持各种情况。比如,在本文发布的时候, Chromium 和 WebRTC 就因为 ninjia 和 gn 工具链的问题,是没有办法在 Mac ARM64 上编译自身架构的。

然后,链接器将目标 .o 文件和各种依赖库,链接到一起,生成可执行可执行文件。
链接过程中,会根据环境变量,查找对应的库文件。通过 ldd 命令就可以看到可执行文件,依赖的库列表。在适配相同指令集不同系统环境的时候,可以考虑将所有的库依赖和二进制可执行文件一起拷贝出来作为编译输出。

而最终生成的可执行文件,无论是 Windows 还是 Linux 平台,都是 COFF(Common File Format) 格式的变种,Windows 下是 PE(Portable Executable),Linux下是 ELF(Executable Linkable Format)。
事实上,除了可执行文件外,动态链接库(DDL,Dynamic Linking Library)、静态链接库(Static Linking Library) 均采用可执行文件格式存储。它们在 Window 下均按照 PE-COFF 格式存储;Linux 下均按照 ELF 格式存储,只是文件名后缀不同而已。
最后,二进制可执行程序在被启动的时候,系统会加载到一个新的地址空间。这也就意味着,系统会从目标文件读取头信息并将程序读入到地址空间段中,用链接器和加载器加载库和进行地址空间转换。然后设置进程各种环境信息和程序参数,最终将程序运行起来,执行程序对应的每条机器指令。
而每个系统环境的库和依赖都不尽相同,可以在通过设置 LD_LIBRARY_PATH 环境变量指定读取的库目录,或者通过 docker 等方案,完整指定一个运行环境。而计算机在读取每一条机器指令再执行的过程中,其实还可以通过虚拟机的方式进行机器指令的转译进行模拟,比如 qemu 能支持多种指令集, Mac rosetta 2 能将 x86_64 高效翻译为 arm64 并执行。
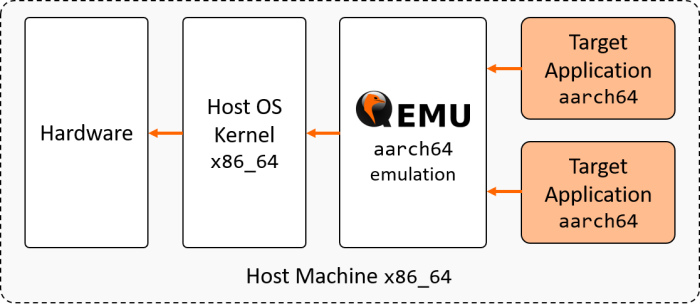
适配与工程效率
通过编译和运行的整个流程分析,我们可以在业界找到很多工具,提升适配的效率。
- 因为追求 CI/CD 快速搭建并且对系统无依赖,我们会采用 docker 的方式进行编译。通过在 Dockerfile 中从零开始安装所有工具和依赖库,可以严格保证每次编译的环境是一致的。
- 在编译阶段,如果依赖较为清晰,可以使用交叉编译的方式,在 x86_64 机器上直接编译对应的程序。如果系统依赖库比较复杂但是代码量比较小的情况下,还可以考虑使用 qemu 模拟对应的指令集进行本地编译,其实就是用 qemu 把 gcc/clang 的指令直接翻译一遍而环境都不需要修改。docker 的 buildx 就是基于这个思路实现的。但是需要注意的是,qemu 是通过指令集翻译的方式来执行的,效率不高,代码量大点的情况下基本不用考虑这个方案了。docker buildx 也还不太稳定,本人不止一次使用 buildx 编译把 docker service 搞挂。
- 代码量大且编译工具依赖较深的情况下,gcc/clang 交叉编译可能不好改造,可以直接在对应的指令集上进行本地编译。具体情况需要看工程实践,代码仓库巨大且改造困难的情况下,甚至可以不同模块一部分使用交叉编译一部分使用模拟或者目标机器本地编译,最后再链接到一起,只要保证工程效率最高即可。
- 特定 CPU 效率优化不同的 CPU,即使是同一个体系结构,支持的具体机器指令也有不同,这些都会影响到执行效率,比如是否能使用到一些长指令。正常的优化流程是,各 CPU 厂家把自己的特性推到 gcc/clang/llvm,作为开发者在编译时就可以使用到了。但是这个过程需要时间,并且对编译器的版本还有要求,所以各 CPU 厂家也会在文档中说明,在编译时可能需要注意 gcc 具体版本,甚至在执行 gcc 命令时增加特殊的参数。
- 我们 RTC 服务使用了 kubernetes 进行服务编排,所以编译产出物其实是 docker images。在面对多指令集架构的时候,选择基础镜像需要更加谨慎。docker 基础镜像通常大家会从 scratch、alpine、debian、debian-slim、ubuntu、centos 里面进行选择。除非特殊要求,否则大家都不会选择 scratch 空镜像从头构建。而 alpine 体积只有 5M,看起来很美好,但是系统 C 库是基于 musl 而不是桌面系统或服务器常见的 glic,重度 C/C++ 应用,尽量不要使用这个版本,否则可能会导致工作量大增。debian-slim 相比于 debian,主要是删除了一些不常用的文件和文档,一般服务可以选择 slim。而 ubuntu 和 centos 都缺少 mips 架构的官方支持,如果工作中要考虑龙芯等 mips CPU 的情况,则可以考虑 debian-slim。另外一点注意的是,很多开源软件的编译验证系统选择的是 ubuntu,而在编译时需要注意的是,ubuntu 是基于 debian unstable 或者 testing 分支的,使用的 C 库版本与 debian 会有差异。
- CI 编译完,可以使用 qemu + docker 启动服务,在一个架构上对多指令集进行简单验证,而不需要依赖与特性的机器和环境。docker 支持将聚合多种架构的 image 聚合到一个 tag,即在不同的机器上,执行docker pull会根据当前系统的指令集和架构,获取对应的镜像。但是这样的设计,在一个系统上,生成和存储多架构,使用和验证时特殊指定一个架构,会较为繁琐。所以我们在工程实践中,直接在 image tag 上标识出了不同的架构,这样生成、获取、验证镜像都非常简单直接。
- 如果最终程序需要在 Native 而非 Docker 环境运行,面对不同的系统依赖,可以通过修改当前进程的LD_LIBRARY_PATH环境变量指定动态库加载路径。在编译生成可执行二进制文件的时候,可以通过执行 ldd 命令,将所有的依赖库拷贝出来,通过 LD_LIBRARY_PATH 指定到对应的路径,可以隔绝对系统库的依赖。有些情况下,因为系统基础 C 库版本不一致,可能会导致可执行二进制文件在链接的情况下就会出问题。这时候可以考虑 patchelf 对 ELF 进行修改,只用指令的 C 库和链接器,隔绝各种环境依赖。
结语
融云一直专注于 IM 和 RTC 领域,无论在公有云或者私有云市场,我们都感受到了市场上对多种 CPU 指令集架构的需求。目前我们针对公有云 AWS/华为 ARM CPU 和信创市场所有的 ARM/MIPS CPU 都进行了全功能的适配和优化,对于信创市场各种操作系统、数据库和中间件也进行了针对性的适配。本文对其中编译适配工程中用到的技术和工具进行了分析,欢迎大家多多交流。